Чтобы создать проблему релевантности необходимо подготовить поисковик. Мы будем использовать ElasticSearch и TMDB датасет (информация о фильмах).
Чтобы проиндексировать фильмы, сначала нужно их загрузить! Для доступа к файлу tmdb.json с данными о фильмах мы будем использовать функцию extract. В следующем фрагменте кода показано, как извлечь каждый фильм, преобразовав JSON-файл в словарь Python.
def extract():
f = open('tmdb.json')
if f:
return json.loads(f.read());Как выглядит возвращаемый словарь?
Это отображение (mapping) идентификаторов фильмов TMDB на сами фильмы, полученные из TMDB. У фильма есть множество полей, которые мы ожидаем увидеть у описания фильма. Посмотрим на пример. Вот фрагмент фильма Aquamarine в виде словаря Python:
{ ...
"title": "Aquamarine",
"tagline": "A Fish-Out-Of-Water Comedy.",
"release_date": "2006-03-03",
"popularity": 0.340685029867431,
"original_title": "Aquamarine",
"budget": 12000000,
"cast": [
{
"name": "Emma Roberts",
"character": "Claire", ...
}
],
"vote_average": 5.6,
"runtime": 104
}Теперь, когда у нас загружены данные, мы будем индексировать эти документы в Elasticsearch.
Elasticsearch предлагает несколько способов индексирования документов. В основном мы будем использовать API пакетного индексирования (bulk index API), который позволяет эффективно индексировать несколько документов за один HTTP-запрос.
Не переживайте о деталях работы bulk index API. Что действительно важно для релевантности — это умение пересоздавать индекс с новым анализатором и новыми настройками. После пересоздания индекса потребуется повторно обработать документы с учётом обновлённых настроек.
Итак, давайте создадим функцию reindex. Функция reindex принимает настройки (settings) и словарь movieDict, возвращённый функцией extract, пересоздаёт индекс в Elasticsearch и загружает туда данные.
import json
import requests
def reindex(analysisSettings={}, mappingSettings={}, movieDict={}):
settings = {
"settings": {
"number_of_shards": 1,
"index": {
"analysis": analysisSettings,
}
}
}
if mappingSettings:
settings['mappings'] = mappingSettings
# Удаляем старый индекс
resp = requests.delete("http://localhost:9200/tmdb")
# Создаем новый индекс с настройками
resp = requests.put(
"http://localhost:9200/tmdb",
data=json.dumps(settings)
)
# Формируем bulk-запрос для индексирования фильмов
bulkMovies = ""
for id, movie in movieDict.iteritems(): # Для Python 3 используйте movieDict.items()
addCmd = {
"index": {
"_index": "tmdb",
"_type": "movie",
"_id": movie["id"]
}
}
bulkMovies += json.dumps(addCmd) + "\n" + json.dumps(movie) + "\n"
# Отправляем bulk-запрос
resp = requests.post(
"http://localhost:9200/_bulk",
data=bulkMovies
)
В функции reindex мы сначала взаимодействуем с Elasticsearch, пересоздавая индекс tmdb.
Создание индекса аналогично созданию базы данных в реляционной СУБД. Индекс будет содержать документы и другие элементы конфигурации поиска для контента TMDB. При работе с индексом tmdb мы будем взаимодействовать с HTTP-эндпоинтом /tmdb в Elasticsearch.
Можно заметить, что в коде передаётся настройка number_of_shards. Частота встречаемости термина в документах (document frequency) является важным компонентом ранжирования результатов. Частота встречаемости считается как количество раз, когда термин встречается во всём индексе. В распределённых поисковых системах, где индекс физически разделяется на шарды, частота встречаемости хранится отдельно для каждого шарда. Это может приводить к некорректному ранжированию результатов для небольших тестовых наборов документов. Для больших наборов данных эффект шардирования обычно нивелируется за счёт усреднения. Для обеспечения повторяемости тестов мы отключаем шардирование.
Далее мы начинаем использовать API пакетного индексирования (bulk index API). Мы формируем строку с bulk-командами для индексирования в Elasticsearch.
addCmd сообщает Elasticsearch метаданные о документе, такие как индекс, в котором он должен храниться (_index: tmdb), его тип (_type: movie) и уникальный идентификатор (берётся из id TMDB).
На следующей строке мы добавляем сам документ, который нужно проиндексировать. Затем мы объединяем команду и документ, добавляя их к строке bulkMovies. Этот процесс повторяется для каждого фильма в movieDict.
Наконец, после формирования полного bulk-запроса, мы отправляем (POST) строку bulkMovies на эндпоинт /bulk в Elasticsearch.
Имея все необходимые части, мы наконец можем проиндексировать фильмы. Объединяя функции extract и reindex, мы можете загрузить данные в Elasticsearch следующим образом:
movieDict = extract()
reindex(movieDict=movieDict)Мы только что построили наш первый ETL-конвейер (extract, transform, load — извлечение, преобразование, загрузка). В этом процессе мы выполнили следующие шаги:
-
Извлекли информацию из внешней системы
-
Преобразовали данные в форму, подходящую для поискового движка
-
Проиндексировали данные в Elasticsearch
Кроме того, указав Elasticsearch через команды в reindex новый индекс (_index: tmdb) и новый тип (_type: movie), мы создали и индекс, и тип документа.
В дальнейшем, когда потребуется выполнять поиск или работать с индексом tmdb, мы будем использовать путь tmdb/movie/ или tmdb/ в URL Elasticsearch.
Поле _type в Elasticsearch раньше использовалось для обозначения типа документа внутри одного индекса. Оно позволяло хранить разные типы документов (например, movie, user, review) в одном индексе, как будто это таблицы в базе данных.
Пример:
{
"_index": "tmdb",
"_type": "movie",
"_id": "123",
"_source": {
"title": "Inception",
"year": 2010
}
}
Исторически:
-
До версии Elasticsearch 6.0 можно было использовать несколько
_typeв одном индексе. -
Начиная с 6.x, начали ограничивать использование типов, т.к. это вызывало путаницу и проблемы с маппингами.
-
В Elasticsearch 7.0 разрешён был только один
_type(обычно_doc). -
В Elasticsearch 8.0 и выше поле
_typeустарело и удалено. Теперь каждый индекс поддерживает только один тип документа, и он не указывается явно — просто опускается.
Почему убрали:
-
Использование
_typeкак логического разделения было неэффективным. -
Это создавало дублирование маппинга, потенциальные конфликты и сложности в обработке данных.
-
Современная практика — один индекс = один тип документа, а логическое разделение делается через поле, например,
doc_type.
Для современных версий Elasticsearch (>7.x) — использовать _type не нужно. Просто указываем _index, _id и _source.
Первые поисковые запросы
Теперь можно приступать к поиску!
Для этого поисковой машине нужно понять, как обрабатывать пользовательские запросы, поступающие из строки поиска приложения. Чтобы это реализовать, мы будем использовать Query DSL (domain-specific language) Elasticsearch — специализированный язык для построения поисковых запросов.
Query DSL позволяет указать Elasticsearch, как именно выполнять поиск, в формате JSON.
С его помощью можно задавать такие параметры, как:
-
обязательные и исключаемые условия (clauses),
-
приоритеты (boosts),
-
веса полей (field weights),
-
функции оценки (scoring functions),
-
и другие параметры, управляющие совпадением и ранжированием результатов.
Query DSL можно считать аналогом SQL, но предназначенным для поисковых движков — языком запросов, ориентированным на ранжированный поиск денормализованных документов.
Поскольку мы только начинаем разбираться в вопросах релевантности, начнём с базового примера — использования запроса multi_match.
Это универсальный инструмент Elasticsearch для построения запросов по нескольким полям одновременно. Поскольку большинство задач поиска затрагивает сразу несколько полей, multi_match — отличная отправная точка.
Типичный старт решения задачи релевантности — попытаться составить multi_match-запрос, где перечисляются поля и добавляются коэффициенты важности (boosts) через символ ^.
Boosting — это способ повлиять на итоговый рейтинг: можно либо добавить к оценке релевантности, либо умножить её на заданное значение.
В нашем случае boosting простой: мы увеличиваем вес поля title в 10 раз, показывая поисковику, что это поле — наиболее важное.
Теперь реализуем функцию поиска, которая принимает Query DSL и выводит результаты в порядке релевантности. Функция search довольно простая: она отправляет запрос и печатает отсортированные результаты — как показано в следующем примере.
import json
import requests
def search(query):
url = 'http://localhost:9200/tmdb/_search'
httpResp = requests.get(url, data=json.dumps(query)) # В Python 3 используйте `json=` вместо `data=`
searchHits = json.loads(httpResp.text)['hits']
print("Num\tRelevance Score\t\tMovie Title")
for idx, hit in enumerate(searchHits['hits']):
print("%s\t%s\t\t%s" % (idx + 1, hit['_score'], hit['_source']['title']))
Как выглядят Query DSL-запросы, которые мы передаём в функцию search?
usersSearch = 'basketball with cartoon aliens'
query = {
"query": {
"multi_match": {
"query": usersSearch,
"fields": ["title^10", "overview"]
}
}
}
search(query)
В листинге выше создаётся поисковый запрос Query DSL с использованием multi_match.
Мы пытаемся сообщить Elasticsearch, что поле title в 10 раз важнее, чем поле overview при ранжировании результатов.
$ python search.py
Num Relevance Score Movie Title
1 0.8424165 Aliens
2 0.5603433 The Basketball Diaries
3 0.52651036 Cowboys & Aliens
4 0.42120826 Aliens vs Predator: Requiem
5 0.42120826 Aliens in the Attic
6 0.42120826 Monsters vs Aliens
7 0.262869 Dances with Wolves
8 0.262869 Interview with the Vampire
9 0.262869 From Russia with Love
10 0.262869 Gone with the Wind
11 0.262869 Fire with Fire
Результаты поиска получились совсем неудачными!
Из запроса «basketball with cartoon aliens» можно предположить, что пользователь, скорее всего, ищет фильм Space Jam — картину, где персонажи Looney Tunes сражаются с инопланетянами в баскетболе при участии Майкла Джордана. Видимо, пользователь не знает названия фильма и пытается найти его при помощи описательного запроса — это довольно типичный сценарий.
К сожалению, большинство фильмов в верхней части списка результатов связаны либо с баскетболом, либо с пришельцами, но не с обоими одновременно. А некоторые фильмы вообще не имеют никакого отношения ни к баскетболу, ни к инопланетянам — то есть мы совсем промахнулись.
А где же Space Jam? Если запросить дополнительные результаты у Elasticsearch, наконец-то можно его увидеть:
43 0.016977157 Space Jam
Почему поисковик решил, что фильмы в топе выдачи — это хорошие результаты?
Как можно диагностировать проблему и начать искать пути её решения?
Работа инженера по релевантности (relevance engineer) — это постоянное поиск и анализ странных, неожиданных результатов, которые возвращает поисковая система.
Нужно найти ответы на два ключевых вопроса:
-
Почему вообще некоторые документы соответствуют условиям запроса?
Почему, например, фильм Fire with Fire вообще оказался среди результатов? -
Почему менее релевантные документы получили высокий рейтинг?
Почему The Basketball Diaries оказался выше Space Jam?
Отладка совпадений в запросе
Что могло пойти не так в неудачном поиске по запросу «basketball with cartoon aliens»?
Первое и основополагающее, с чего стоит начать поиск причин — это отладка поведения совпадения терминов (term-matching) в запросе.
В работе можно часто столкнуться с ситуациями, когда релевантный документ, который должен был совпасть, не попадает в результаты. Или наоборот — когда какие-то малозначимые или случайные термины всё же совпадают, в результате чего в выдаче оказываются нерелевантные документы.
Даже среди документов, которые попали в результаты поиска, то, совпадает или не совпадает термин, может существенно повлиять на оценку релевантности: плохой результат может оказаться на вершине, а хороший — низко в списке, из-за ложных совпадений или неожиданных промахов.
Нужно уметь разбираться в ситуации с помощью инструментов анализа и отладки запросов в Elasticsearch.
Что такое совпадение? Совпадение термина в обратном индексе (inverted index) — это строгое, точное бинарное совпадение.
Поисковики не обладают интеллектом — они не понимают, что “Aliens” и “alien” обозначают одну и ту же идею. Или что “extraterrestrial” — это почти то же самое. Человек, говорящий на английском, интуитивно понимает, что всё это относится к теме инопланетяне”, или, как мы обсуждали ранее, представляет собой признак “инопланетности” в тексте.
Но для “неразумного” поискового движка это просто разные строки в кодировке UTF-8.
Например:
-
"Aliens"— это байты0x41, 0x6c, 0x69, 0x65, 0x6e, 0x73 -
"alien"— это байты0x61, 0x6c, 0x69, 0x65, 0x6e
Они не совпадают, и поэтому поисковик не считает их одинаковыми.
Такое строгое поведение указывает на два важных аспекта, которые нужно анализировать:
-
Query parsing — как запрос Query DSL преобразуется в стратегию сопоставления конкретных терминов с полями.
-
Analysis — как из текста запроса и документа создаются токены (анализ текста).
Понимая процесс query parsing, мы можем точно увидеть, как запрос в Query DSL использует структуры данных Lucene для поиска по разным полям.
А через анализ (analysis) — можно “помять”, “пощупать”, “покопать” текст, чтобы попытаться выделить в нём настоящую “инопланетность” (alien-ness) в виде одного ключевого токена.
Также можно определить бессмысленные термины, которые совпадают, но не несут важной смысловой нагрузки — они создают ложные совпадения по незначимым словам.
Только разобравшись, как создаются и используются базовые структуры данных, можно надеяться контролировать поведение поиска.
Теперь давайте пошагово разберём наш запрос — и проверим, не из-за ли случайных совпадений, вроде Fire with Fire, наш поиск сбился с курса.
Анализ стратегии выполнения запроса
Первое, что мы сделаем для изучения поведения совпадений — это попросим Elasticsearch пояснить, как был разобран наш запрос.
Это позволит разложить поисковый запрос на альтернативное представление, которое более точно отражает, как Elasticsearch взаимодействует с низкоуровневыми структурами данных Lucene.
Для этого мы воспользуемся эндпоинтом валидации запроса (query validation endpoint).
Этот эндпоинт, как показано в следующем листинге, принимает на вход запрос в формате Query DSL и возвращает низкоуровневое описание стратегии, которую Elasticsearch использует для выполнения запроса.
import json
import requests
query = {
"query": {
"multi_match": {
"query": usersSearch,
"fields": ["title^10", "overview"]
}
}
}
url = 'http://localhost:9200/tmdb/movie/_validate/query?explain'
httpResp = requests.get(url, data=json.dumps(query)) # Для Python 3 лучше использовать `json=query`
print(json.loads(httpResp.text))
Ответ:
{
"_shards": {
"failed": 0,
"successful": 1,
"total": 1
},
"explanations": [
{
"explanation": "filtered((((title:basketball title:with title:cartoon title:aliens)^10.0) | (overview:basketball overview:with overview:cartoon overview:aliens)))->cache(_type:movie)",
"index": "tmdb",
"valid": true
}
],
"valid": true
}
Здесь поле explanation содержит именно то, что нас интересует.
Запрос был преобразован в более точный синтаксис, который даёт более глубокое представление о том, как Lucene будет работать с запросом, переданным в Elasticsearch:
((title:basketball title:with title:cartoon title:aliens)^10.0) |
(overview:basketball overview:with overview:cartoon overview:aliens)
Разбор парсинга запроса
Эндпоинт валидации запроса вернул альтернативное представление запроса в Query DSL, чтобы помочь в отладке проблем с выдаче.
Результат валидации напоминает синтаксис запроса Lucene — это низкоуровневый и точный способ задания поиска.
Благодаря этой дополнительной точности синтаксис Lucene позволяет более детально описать, какие условия должен удовлетворять релевантный документ, и делает это ближе к тому, как Lucene реально работает с инвертированным индексом.
запросы Lucene состоят из булевых условий:
-
MUST(+) — обязательно должно совпасть, -
SHOULD— желательно совпадение (даёт очки, но не обязательно), -
MUST_NOT(-) — должно не совпадать.
Каждое условие указывает, по какому полю нужно искать, и имеет формат:
[+/-]<имя_поля>:<поисковый_термин>
Для отладки совпадений нас больше всего интересует часть <имя_поля>:<термин>.
Например, title:basketball означает, что нужно искать совпадение слова basketball в поле title.
Каждое такое условие — это простой term query — поиск одного термина в инвертированном индексе.
Кроме term-запросов, часто встречаются фразовые запросы (phrase queries), которые ищут слова, стоящие рядом. Они задаются через кавычки, например: title:"space jam" — это значит, что термины space и jam должны быть рядом друг с другом.
Можно заметить четыре SHOULD-условия, сгруппированные в скобки:
(title:basketball title:with title:cartoon title:aliens)
Эта группа была усилена коэффициентом 10, как мы и указали в Query DSL:
(title:basketball title:with title:cartoon title:aliens)^10
И затем эта группа сравнивается с аналогичной по overview, при этом результат с максимальной оценкой выбирается с помощью оператора | (или):
((title:basketball title:with title:cartoon title:aliens)^10.0) |
(overview:basketball overview:with overview:cartoon overview:aliens)
Отладка анализа текста для устранения проблем с совпадением
Теперь, когда мы знаем, какие термины ищет поисковик, следующий шаг в отладке — это понять, как документы разбиваются на термины и попадают в индекс. Ведь если нужные термины не присутствуют в индексе, то поиск по ним просто не сработает.
Мы уже рассматривали такой пример:
Поиск по термину “Aliens” не найдёт документ с “alien”, несмотря на нашу интуицию.
Более того, некоторые термины могут давать ложные совпадения, не несущие никакой полезной информации. Например, совпадение по слову the в английском языке почти всегда бессмысленно — оно не несёт важного признака, который мог бы быть полезен пользователю.
Несмотря на то, что у нас есть интуитивное представление о том, как документ должен быть разобран на термины, механика анализа часто преподносит сюрпризы. Это процесс, который придётся отлаживать регулярно.
Как именно извлекаются термины?
Через анализ на этапе индексирования (index-time analysis).
В Elasticsearch этот процесс определяет анализатор (analyzer). Он состоит из компонентов, которые были описаны здесь
-
Фильтры символов (character filters)
-
Токенизатор (tokenizer)
-
Фильтры токенов (token filters)
В Elasticsearch анализатор можно задать на разных уровнях:
-
для всего индекса (например,
tmdb), -
для конкретного узла (инстанса Elasticsearch),
-
для конкретного поля,
-
и даже на уровне запроса (query-time analyzer).
Пока мы явно не указывали анализатор, поэтому используется анализатор по умолчанию — standard analyzer.
Используя эти знания и специальный эндпоинт /analyze, мы можем посмотреть, как текст из документов преобразуется в токены, которые затем записываются в обратный индекс.
Возможно, если посмотреть, как анализируется заголовок “Fire with Fire”, мы увидим, какие именно термины из него попадают в индекс, и тогда станет ясно, почему этот, казалось бы, случайный и нерелевантный фильм оказался в результатах поиска.
import requests
resp = requests.get(
'http://localhost:9200/tmdb/_analyze?analyzer=standard&format=yaml',
data="Fire with Fire"
)
print(resp.text)
Результат:
tokens:
- token: "fire"
start_offset: 0
end_offset: 4
type: "<ALPHANUM>"
position: 1
- token: "with"
start_offset: 5
end_offset: 9
type: "<ALPHANUM>"
position: 2
- token: "fire"
start_offset: 10
end_offset: 14
type: "<ALPHANUM>"
position: 3
Пояснение:
-
token— это извлечённое слово. -
start_offsetиend_offsetуказывают на позицию слова в исходной строке. -
typeговорит о типе токена (в данном случае<ALPHANUM>— слово, состоящее из букв/цифр). -
position— это порядковая позиция токена в последовательности (используется при анализе фраз и расстояний между словами).
Цель поискового движка при индексировании — обработать поток токенов и поместить его в инвертированный индекс, распределяя документы по соответствующим терминам.
После подсчёта количества вхождений определённого токена (в данном случае, двух экземпляров слова fire), система добавляет записи в список вхождений (postings list) для термина fire.
Под термином fire добавляется наш документ — документ 0 (doc 0).
Также сохраняется:
-
частота вхождений (freq) — сколько раз слово fire встретилось в
doc 0, -
позиции (position entries) — где именно в тексте находился каждый экземпляр fire.
Вместе с этим, поскольку в документе присутствует и слово with, он также будет добавлен в список вхождений для термина with.
В результате один и тот же документ будет находиться в списках вхождений сразу для двух терминов: fire и with, как показано в следующем листинге.
field title
term fire
doc 0
freq 2
position 1
position 3
doc 2
...
term with
doc 0
freq 1
position 2
Сравнение запроса с обратным индексом
Теперь мы готовы сравнить разобранный (parsed) запрос с данными, содержащимися в обратном индексе.
Если взять наш разобранный запрос:
((title:basketball title:with title:cartoon title:aliens)^10.0) |
(overview:basketball overview:with overview:cartoon overview:aliens)
и сравнить его с фрагментом инвертированного индекса, полученным из потока токенов документа Fire with Fire, становится ясно, где именно происходит совпадение.
Условие title:with подтягивает в результаты doc 0 — Fire with Fire из инвертированного индекса. Вспоминая, как работают совпадения терминов, становится понятно, в чём суть механизма: наш документ присутствует в индексе под термином with, а значит, автоматически попадает в результаты поиска вместе с другими документами, содержащими этот термин.
Для носителей английского языка совпадение по слову with не несёт никакой пользы и лишь вызывает недоумение: почему такое шумовое слово было воспринято как значимое при совпадении?
И другие случайные фильмы попадают в ту же категорию. Фильмы вроде Dances with Wolves или From Russia with Love также легко «засасываются» в результаты, как и те документы, которые действительно содержат важные термины — например, basketball или aliens.
Без дополнительной настройки поисковик не способен отличить осмысленные, значимые и важные английские слова от шумовых и малозначимых.
Исправляем проблему совпадений с помощью смены анализатора
К счастью, у этой проблемы с совпадениями есть простое решение. Мы немного подшутили над Elasticsearch за его незнание английского, но на самом деле в Elasticsearch есть анализатор, который весьма неплохо обрабатывает английский текст.
Он объединяет в себе фильтры символов, токенизатор и фильтры токенов, чтобы привести английские слова к стандартным формам. Такой анализатор умеет:
-
приводить слова к корневой форме (running → run),
-
удалять “шумовые” слова вроде the, которые называются стоп-словами (stop words).
К нашему счастью, слово with — это как раз такое стоп-слово.
Если оно будет удалено из индекса, проблема ложных совпадений может исчезнуть.
Как использовать этот анализатор? Очень просто:
нужно просто назначить другой анализатор для нужных полей.
Поскольку изменения анализа на этапе индексирования затрагивают структуру инвертированного индекса, документы потребуется переиндексировать.
Чтобы настроить анализ, нужно пересоздать индекс и заново выполнить код индексирования.
И действительно, совпадения становятся гораздо ближе к тому, что нужно.
По крайней мере, теперь мы находимся в области «инопланетян».
Более того, благодаря более продвинутому анализу, стеммингу и нормализации токенов, система теперь находит и другие совпадения по термину alien, которые раньше пропускались.
Num Relevance Score Movie Title
1 1.0643067 Alien
2 1.0643067 Aliens
3 1.0643067 Alien³
4 1.0254613 The Basketball Diaries
5 0.66519165 Cowboys & Aliens
6 0.66519165 Aliens in the Attic
7 0.66519165 Alien: Resurrection
8 0.53215337 Aliens vs Predator: Requiem
9 0.53215337 AVP: Alien vs. Predator
10 0.53215337 Monsters vs Aliens
11 0.08334568 Space Jam
Отладка ранжирования
После того как мы решили проблему с совпадениями, остаётся вопрос — почему такие фильмы, как Alien, Aliens и The Basketball Diaries, находятся выше в результатах, чем Space Jam? Ни один из них не рассказывает о пришельцах, играющих в баскетбол. Пользователь по-прежнему остаётся разочарованным. С такими результатами он, скорее всего, начинает терять терпение к поисковому приложению.
Нам необходимо разобраться в механике ранжирования по релевантности и настроить её так, чтобы она лучше соответствовала информационным потребностям пользователя.
И для этого — нам придётся попросить Elasticsearch объяснить свои действия.
Чтобы отлаживать ранжирование, нужно понимать две ключевые вещи:
-
Как рассчитывается оценка совпадения (match score) для каждого термина
-
Как эти оценки влияют на общую оценку релевантности документа
В основе всего лежит оценка (score). Это число, которое поисковая система присваивает документу, совпавшему с запросом. Оно указывает, насколько документ релевантен (чем выше оценка — тем выше релевантность). Соответственно, ранжирование — это, по сути, сортировка документов по этому числу.
В процессе отладки ранжирования станет понятно, что хотя эта оценка строится на теоретической модели, её поведение полностью в наших руках.
Для каждого совпадения нужно задать себе вопрос: насколько оценка совпадения действительно отражает силу соответствующего признака?
Мы уже говорили, что все упоминания alien или связанных понятий (например, Aliens или extraterrestrial) усиливают проявление признака «инопланетности» (alien-ness) в тексте.
Но ощущается ли, что совпадение по слову alien действительно отражает эту «инопланетность» в нужной степени?
Чтобы ответить на этот вопрос, мы разберём математическую формулу, по которой рассчитывается оценка термина. Только после этого можно будет осмысленно судить, отражают ли совпадения по alien или basketball нашу интуицию относительно насыщенности фильма инопланетянами или баскетболом.
Разбор оценки релевантности
((title:basketbal title:cartoon title:alien)^10.0) |
(overview:basketbal overview:cartoon overview:alien)
В этом запросе мы ищем термины basketbal (стем-форма от basketball), cartoon и alien в каждом из двух полей. Оценка по полю title усиливается в 10 раз (^10). Затем поисковик выбирает максимальную оценку из двух полей (что задаётся оператором |).
Это хорошая отправная точка, но сейчас нам важен не общий подход, нужно увидеть арифметику оценки для конкретных документов.
Давайте теперь повторим наш запрос, добавив explain: true, чтобы можно было проанализировать, как именно рассчитывается оценка.
import json
import requests
query = {
"explain": True,
"query": {
"multi_match": {
"query": usersSearch,
"fields": ["title^10", "overview"]
}
}
}
httpResp = requests.get(
'http://localhost:9200/tmdb/movie/_search',
data=json.dumps(query)
)
jsonResp = json.loads(httpResp.text)
print("Explain for %s" % jsonResp['hits']['hits'][0]['_source']['title'])
print(json.dumps(jsonResp['hits']['hits'][0]['_explanation'], indent=2))
вот фрагмент JSON-вывода explain для фильма Alien:
{
"description": "max of:",
"value": 1.0643067,
"details": [
{
"description": "product of:",
"value": 1.0643067,
"details": [
{
"description": "sum of:",
"value": 3.19292,
"details": [
{
"description": "weight(title:alien in 223) [PerFieldSimilarity], result of:",
"value": 3.19292,
"details": [
{
"description": "score(doc=223,freq=1.0 = termFreq=1.0), product of:",
"value": 3.19292,
"details": [
{
"description": "queryWeight, product of:",
"value": 0.4793294,
"details": [
{
"description": "idf(docFreq=9, maxDocs=2875)",
"value": 6.661223
}
// <опущено>
]
}
]
}
]
}
]
}
]
}
]
}
Упрощённый explain для Alien
1.0646985, max of:
1.0646985, product of:
3.1940954, sum of:
3.1940954, weight(title:alien in 223) [PerFieldSimilarity], result of:
3.1940954, score(doc=223, freq=1.0 = termFreq=1.0), product of:
0.4793558, queryWeight, product of:
6.6633077, idf(docFreq=9, maxDocs=2881)
0.07193962, queryNorm
6.6633077, fieldWeight in 223, product of:
1.0, tf(freq=1.0), with freq of:
1.0, termFreq=1.0
6.6633077, idf(docFreq=9, maxDocs=2881)
1.0, fieldNorm(doc=223)
0.33333334, coord(1/3)
0.053043984, product of:
0.15913194, sum of:
0.15913194, weight(overview:alien in 223) [PerFieldSimilarity], result of:
0.15913194, score(doc=223, freq=1.0 = termFreq=1.0), product of:
0.033834733, queryWeight, product of:
4.7032127, idf(docFreq=70, maxDocs=2881)
0.0071939616, queryNorm
4.7032127, fieldWeight in 223, product of:
1.0, tf(freq=1.0), with freq of:
1.0, termFreq=1.0
4.7032127, idf(docFreq=70, maxDocs=2881)
1.0, fieldNorm(doc=223)
0.33333334, coord(1/3)
Сравним этот explain для Alien с explain для нашего целевого результата — Space Jam:
0.08334568, max of:
0.08334568, product of:
0.12501852, sum of:
0.08526054, weight(overview:basketbal in 1289) [PerFieldSimilarity], result of:
0.08526054, score(doc=1289, freq=1.0 = termFreq=1.0), product of:
0.049538642, queryWeight, product of:
6.8843665, idf(docFreq=7, maxDocs=2875)
0.0071958173, queryNorm
1.7210916, fieldWeight in 1289, product of:
1.0, tf(freq=1.0), with freq of:
1.0, termFreq=1.0
6.8843665, idf(docFreq=7, maxDocs=2875)
0.25, fieldNorm(doc=1289)
0.03975798, weight(overview:alien in 1289) [PerFieldSimilarity], result of:
0.03975798, score(doc=1289, freq=1.0 = termFreq=1.0), product of:
0.03382846, queryWeight, product of:
4.701128, idf(docFreq=70, maxDocs=2875)
0.0071958173, queryNorm
1.175282, fieldWeight in 1289, product of:
1.0, tf(freq=1.0), with freq of:
1.0, termFreq=1.0
4.701128, idf(docFreq=70, maxDocs=2875)
0.25, fieldNorm(doc=1289)
0.6666667, coord(2/3)
На первый взгляд, explain’ы могут показаться пугающими. Но важно понять, что explain — это всего лишь пошаговая декомпозиция арифметики, стоящей за оценкой релевантности.
Каждое число на верхнем уровне объясняется более глубокими деталями, вложенными внутрь.
На самом верхнем уровне мы видим общую оценку релевантности документа.
Чем глубже мы спускаемся, тем подробнее раскрывается, из чего складывается эта оценка.
В конце концов, мы доходим до уровня, где перечислены оценки отдельных совпадений, например title:alien.
Под этим уровнем описываются компоненты, участвующие в вычислении оценки для конкретного совпадения в поле.
Этот уровень можно считать границей между двумя частями объяснения:
-
Внутри: производится оценка конкретного совпадения на основе структур данных Lucene.
-
Снаружи: эти оценки объединяются в более общую формулу.
Если скрыть детали внутри каждого совпадения и посмотреть только на внешние операции,
мы получим ещё более сжатую версию объяснения для Alien:
1.0643067, max of:
1.0643067, product of:
3.19292, sum of:
3.19292, weight(title:alien in 223) [PerFieldSimilarity]
0.33333334, coord(1/3)
0.066263296, product of:
0.19878988, sum of:
0.19878988, weight(overview:alien in 223) [PerFieldSimilarity]
В результате остаётся набор операций над совпадениями. Внутри такие операции представляют собой запросы, которые оборачивают другие запросы — их называют составными (compound queries).
Составные запросы позволяют описывать, как разные признаки, представленные оценками совпадений терминов, связаны между собой математически. Они отражают стратегию запроса, которую мы уже видели:
((title:basketbal title:cartoon title:aliens)^10.0) |
(overview:basketbal overview:cartoon overview:aliens)
После объединения совпадений, они, в свою очередь, могут быть вложены в другие составные (compound) запросы на любой глубине, создавая ещё более сложные конструкции оценки и совпадения. Значительная часть инженерии релевантности — это понимание того, как запрос Query DSL преобразуется в набор составных запросов.
Если заглянуть под капот и рассмотреть, что происходит внутри конкретного совпадения, можно увидеть совершенно другой тип вычислений. Оценка начинает выглядеть более запутанно, наполненной специализированной терминологией поисковых систем.
Здесь появляется информация о статистике совпадений для конкретного поля — это базовые строительные блоки оценки, которые (в идеале) должны точно отражать силу определённого скрытого признака в тексте.
Векторная модель
Большая часть формулы расчета в Lucene происходит из области информационного поиска (information retrieval).
Хотя теория даёт полезный контекст для понимания проблемы, на практике оценка релевантности использует эвристики, основанные на прикладном опыте — на том, что реально работает.
Во многом, за пределами базовых концепций, оценка релевантности — это искусство.
Понимание научной основы поможет правильно измерять вес признаков, скрытых в тексте.
В информационном поиске поиск по нескольким терминам в поле (например, наш запрос
overview:basketbal overview:alien overview:cartoon для Space Jam) приближённо моделируется как сравнение векторов между запросом и найденным документом.
Векторы? Это звучит как геометрия, а не решение задачи в области обработки языка!
Но давайте вспомним: вектор — это величина и направление в пространстве. Вектор часто изображают как стрелу, идущую из начала координат — например, от Земли к Луне.
В числовом выражении вектор — это набор значений по каждой оси. Например, вектор <50, 20> может означать “на север 50 миль, на восток 20 миль”.
Пространство векторов при этом не обязательно связано с физическим миром —
оно может быть абстрактным, например, пространством признаков текста.
Например, если ось X представляет собой сочность фрукта, а ось Y — его размер,
то можно определить векторное пространство, которое будет отражать важные характеристики “фруктовости”.

Здесь показаны несколько фруктов, представленных вектором в пространстве «сочность/размер». Одни имеют выраженную силу по оси сочности, другие — по оси размера.
Легко увидеть, как похожие фрукты группируются рядом друг с другом. Например, фрукты в правом верхнем углу, скорее всего, — это арбузы: очень большие и очень сочные.
Можно сделать вывод о сходстве двух фруктов, вычисляя скалярное произведение их векторов. В нашем примере с фруктами это означает:
-
Перемножить значения сочности двух фруктов,
-
Перемножить их размеры,
-
Сложить полученные результаты.
Иными словами: чем больше свойств у фруктов совпадает, тем выше значение скалярного произведения.
dotprod(fruit1, fruit2) = juiciness(fruit1) × juiciness(fruit2) +
size(fruit1) × size(fruit2)
Причём здесь текст?
В информационном поиске текст (запросы и документы) тоже можно представить векторами. Только вместо признаков вроде сочности или размера, размерности в векторном пространстве текста будут представлять слова, встречающиеся в тексте.
Например, вместо фруктов мы можем рассматривать обзоры фильмов, где упоминаются “баскетбол”, “пришельцы” или “мультфильмы”
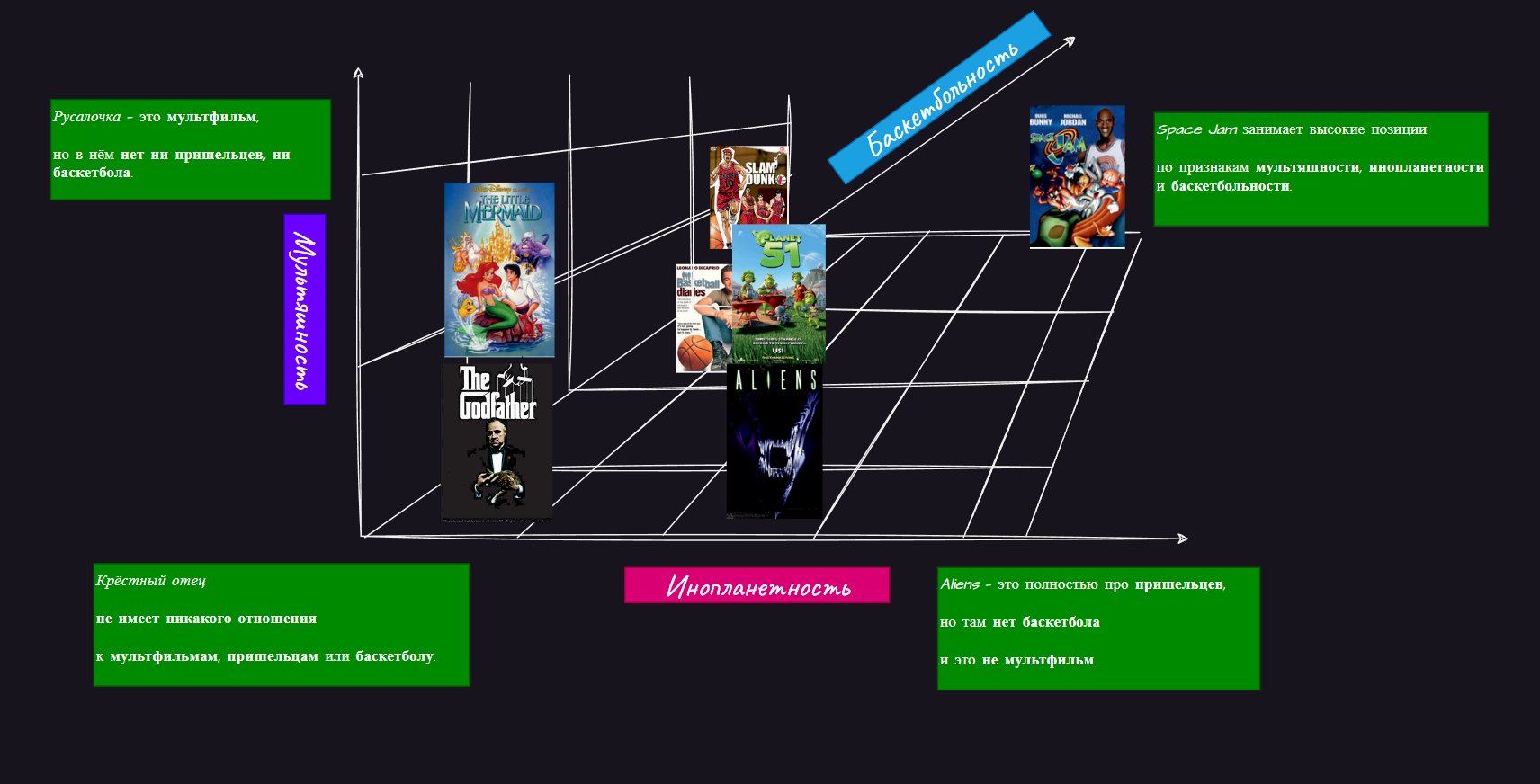
-
Какие-то тексты явно говорят о пришельцах (например, обзор фильма Alien),
но не о баскетболе или мультфильмах. -
Другие тексты (например, обзор японского аниме Slam Dunk)
говорят о баскетболе и мультфильмах, но не о пришельцах.
Мы предполагаем, что наш целевой фильм Space Jam должен иметь высокие оценки по всем трём признакам.
Точно так же, как у фрукта есть признак «сочности», можно рассматривать текст фильма как обладающий признаком «инопланетности», основанным на частоте встречаемости слов, связанных с пришельцами.
Чтобы обобщить эту идею представления признаков, мы вводим понятие пространства признаков (feature space) — это векторное пространство, где каждое измерение соответствует определённому признаку, независимо от того, говорим ли мы о признаках фруктов, текста или чего-либо ещё, что стоит сравнивать.
Разумеется, фильмы посвящены не только баскетболу, мультфильмам и пришельцам.
Пространство признаков текста значительно больше трёх измерений.
В так называемой модели мешка слов (bag of words model) вектор имеет отдельное измерение для каждого возможного термина.
Теоретически, можно создать измерение для каждого слова в языке!
Конечно, в реальности ни один документ или запрос не будет содержать все слова языка. Вряд ли в обзоре Space Jam будет упоминание о Риме или истории. Точно так же в обзоре Gladiator вряд ли будет упоминание Майкла Джордана.
Именно поэтому большинство размерностей в таких векторах будут пустыми или нулевыми — такие вектора называют разрежёнными (sparse vectors).
Баскетбольность
Когда становится ясно, что каждое измерение вектора — это определённый признак,
следующий шаг — измерить силу или величину этого признака.
В поиске это значение называется весом (weight) — показателем того, насколько важен данный термин для конкретного текста.
-
Если термин alien является определяющим — он должен получить высокий вес.
-
Иначе— его вес будет низким или нулевым.
Если снова взглянуть на ранее рассмотренное объяснение (explain), можно увидеть, как Lucene оценивает “инопланетность” в Space Jam:
0.03975798, weight(overview:alien in 1289)
Прежде чем углубляться в то, как Lucene вычисляет этот вес, давай рассмотрим пример с более простой формулировкой.
Определим вес для конкретного термина в тексте так:
-
если термин присутствует хотя бы один раз, вес равен 1;
-
если термин отсутствует, вес равен 0.
Согласно такому определению, отрывок текста из обзора Space Jam: “basketball game against alien” будет представлен в виде следующего вектора Vd:
| Слово | Вес (0 или 1) |
|---|---|
| a | 0 |
| alien | 1 |
| against | 1 |
| … | 0 |
| basketball | 1 |
| Cartoon | 0 |
| … | 0 |
| game | 1 |
| … | 0 |
| movie | 0 |
| narnia | 0 |
| … | 0 |
| zoo | 0 |
| Этот вектор имеет измерение для каждого слова английского языка; мы показываем здесь только небольшую часть английских слов. |
Можно сравнить его с аналогично построенным вектором Vq для запроса “basketball with cartoon aliens”.
| Слово | Вес (0 или 1) |
|---|---|
| a | 0 |
| alien | 1 |
| against | 0 |
| … | 0 |
| basketball | 1 |
| cartoon | 1 |
| … | 0 |
| game | 0 |
| … | 0 |
| movie | 0 |
| narnia | 0 |
| … | 0 |
| zoo | 0 |
Сколько компонентов совпадает? Насколько похожи запрос и документ?
Точно так же, как в примере с фруктами, можно вычислить скалярное произведение (dot product), чтобы получить оценку сходства.
скалярное произведение двух векторов — это поэлементное перемножение соответствующих компонентов, а затем суммирование всех результатов.
Оценка для нашего запроса рассчитывается следующим образом:
score = Vd['a'] × Vq['a'] + Vd['alien'] × Vq['alien'] + …
+ Vd['space'] × Vq['space'] + …
Если сравнить это с ранее приведённым разбором explain: каждый множитель в скалярном произведении представляет собой результат совпадения по одному признаку.
Иными словами:
-
В explain выражение
overview:alien -
соответствует произведению
Vd['alien'] × Vq['alien'].
Отличие состоит в том, что в explain используется специальная функция Lucene для расчёта веса поля или запроса.
Сама операция суммирования в скалярном произведении отражается в поведении булевого запроса (Boolean query), который складывает совпавшие условия.
Это можно увидеть в предыдущем объяснении в строке:
3.19292, sum of:
3.19292, weight(title:alien in 223) [PerFieldSimilarity]
Ограничения векторной модели
Хотя векторная модель предоставляет общую основу для обсуждения принципов оценки в Lucene, она далека от полного описания реальности.
На практике было выявлено множество эмпирических корректировок (“fudge factors”),
которые значительно улучшают качество ранжирования.
Одно из самых фундаментальных отличий: способы объединения совпадений через составные запросы (compound queries) не всегда сводятся к простому суммированию.
Мы уже видели, что с помощью символа | (ИЛИ) часто берётся максимум (“max”) из оценок двух полей, а не их сумма. Часто в расчётах используется также коэффициент координации (coord factor), который напрямую наказывает составные совпадения, если они пропускают какие-то компоненты.
Коэффициент coord умножает итоговое скалярное произведение на отношение:
число совпавших терминов / общее количество терминов в запросе
Многие составные запросы, с которыми вы столкнетесь, будут выполнять различные операции над базовыми запросами, например:
-
брать максимум (max),
-
суммировать (sum),
-
перемножать (product).
У нас есть огромная свобода: можно произвольно пересчитывать или усиливать (boost) оценки, используя собственные функции запросов (function queries), комбинируя результаты совпадений с другими факторами.
Важно отметить, что результат скалярного произведения часто нормализуется
путём деления на произведение длин обоих векторов:
score =
(Vd['a'] × Vq['a'] + Vd['alien'] × Vq['alien'] + … + Vd['space'] × Vq['space'])
/
(||Vq|| × ||Vd||)
При вычислении скалярного произведения, нормализация переводит итоговую оценку в диапазон от 0 до 1.
Это позволяет сбалансировать уравнение, учитывая как признаки с большими весами, так и признаки с малыми весами.
Важно:
В условиях множества эмпирических поправок в системе оценки Lucene и особенностей статистики полей, никогда не следует напрямую сравнивать оценки между разными запросами, если только вы не выполнили глубокую настройку, чтобы сделать их сопоставимыми.
Как уже упоминалось ранее, разрежённое представление текста известно как модель мешка слов (bag of words model).
Её называют “мешком”, потому что она разлагает текст на отдельные слова, игнорируя контекст появления этих терминов.
Однако: позиция появления термина в тексте является важной частью контекста,
особенно для поиска по фразам (phrase matching).
К счастью, Lucene также сохраняет позиции каждого вхождения термина.
Таким образом, документ можно представить как:
-
разрежённый вектор,
-
который включает все возможные подфразы (subphrases).
И такой вектор может быть очень большим!
И это ещё больше усложняется, если использовать библиотеку сложных span-запросов.
| Слово или фраза | Вес (0 или 1) |
|---|---|
| a | 0 |
| an | 0 |
| alien | 1 |
| … | 0 |
| Basketball | 0 |
| lump | 1 |
| … | 1 |
| ”basketball game” | 1 |
| ”game against” | 1 |
Оценка совпадений для измерения релевантности
Мы всё ещё пытаемся разобраться, почему некоторые фильмы в выдаче оказались подозрительно выше целевого Space Jam.
Мы уже изучили explain’ы и увидели некоторые оценки совпадений, которые вызывают вопросы.
Мы почти у цели!
Теперь нужно понять, как Lucene измеряет вес термина в тексте документа или запроса при построении вектора.
После этого мы сможем оценить, насколько эти веса соответствуют нашим интуитивным ожиданиям о силе совпадений.
Конечно, пользователи не думают в терминах математики, представленной здесь.
Но экспериментально доказано, что такие метрики довольно хорошо приближают общее восприятие релевантности пользователями.
Рассмотрим вычисление веса термина alien в Space Jam, чтобы понять, почему совпадение с этим словом оказалось относительно слабым:
0.03975798, weight(overview:alien in 1289) [PerFieldSimilarity], result of:
0.03975798, score(doc=1289,freq=1.0 = termFreq=1.0), product of:
0.03382846, queryWeight, product of:
4.701128, idf(docFreq=70, maxDocs=2875)
0.0071958173, queryNorm
1.175282, fieldWeight in 1289, product of:
1.0, tf(freq=1.0), with freq of:
1.0, termFreq=1.0
4.701128, idf(docFreq=70, maxDocs=2875)
0.25, fieldNorm(doc=1289)
Как работает вычисление веса в Lucene:
В Lucene вычисление веса устроено следующим образом:
-
Перемножаются два компонента:
-
fieldWeight — насколько термин важен в тексте документа (например, в поле overview).
-
queryWeight — насколько термин важен в тексте запроса пользователя.
-
Информация о весах может быть переведена из explain в разрежённые векторы для запроса и двух оцениваемых документов (Vq и Vd из предыдущего раздела).
Например, если сравнить вес термина alien в Space Jam с соответствующим значением в Alien, то получим:
0.15913194, weight(overview:alien in 223) [PerFieldSimilarity], result of:
0.15913194, score(doc=223,freq=1.0 = termFreq=1.0), product of:
0.033834733, queryWeight, product of:
4.7032127, idf(docFreq=70, maxDocs=2881)
0.0071939616, queryNorm
4.7032127, fieldWeight in 223, product of:
1.0, tf(freq=1.0), with freq of:
1.0, termFreq=1.0
4.7032127, idf(docFreq=70, maxDocs=2881)
1.0, fieldNorm(doc=223)
Эти веса можно представить в виде разрежённого вектора. Здесь приведено значение веса для термина alien.
| Запрос или поле | alien | … |
|---|---|---|
| Запрос: basketball with cartoon aliens (Vq) | 0.033834733 | … |
| Поле overview в Space Jam (Vd) | 1.175282 | … |
| Поле overview в Alien (Vd) | 4.7032127 | … |
| По какой-то причине вес термина alien в поле overview для фильма Alien значительно выше, чем для Space Jam. Для нас это означает, что признак «инопланетности» оценивается как очень сильный в этом тексте обзора. |
Вычисление весов через TF × IDF
Правила расчёта веса термина в поле определяются тем, что в Lucene называется similarity (похожесть).
Similarity использует статистику, записанную в индексе для совпавших терминов, чтобы помочь запросу вычислить числовой вес термина.Lucene поддерживает несколько реализаций similarity, включая возможность определить свою собственную.
Большинство методов основаны на формуле TF × IDF. Она предполагает перемножение двух важных статистик термина, извлечённых из поля и записанных в инвертированном индексе Lucene:
-
TF (Term Frequency) — частота термина,
-
IDF (Inverse Document Frequency) — обратная частота документа.
По умолчанию, важность терминов оценивается именно через их произведение TF × IDF.
-
TF (tf в предыдущих расчётах) показывает,
как часто термин встречается в конкретном поле.
В упрощённой версии инвертированного индекса это значение видно как freq.TF очень важен для оценки совпадений:
если термин часто встречается в тексте поля документа (например, alien упоминается много раз), считается, что текст в большей степени посвящён этому термину.
-
IDF (idf в предыдущих расчётах) показывает,
насколько редким (и, соответственно, ценным) является совпавший термин.Так как IDF — это обратная величина от частоты документа (DF),
он вычисляется как:IDF = 1 / DFГде DF — это количество документов, в которых встречается данный термин.
Если термин редкий, он получает высокий IDF. Например, термин supercalifragilistic встречается всего в одном документе — и получает очень высокий IDF.
Таким образом, базовая формула TF × IDF измеряет важность термина, перемножая частоту появления термина и его редкость:
TF × (1 / DF) = TF / DF
Это позволяет понять, какая доля общего использования термина в индексе сосредоточена в данном документе.
Пример
Таблица 3.1 показывает, как работает TF × IDF.
-
При оценке важности термина lego —
фильмов о Лего относительно мало. -
Поэтому фильм The Lego Movie, где упоминается Лего,
получает высокий TF × IDF вес.
Для сравнения, термин love встречается в огромном числе фильмов (все любят романтические комедии!). Из-за этого упоминания love в одном конкретном фильме, например в Sleepless in Seattle, получают более низкий вес, чем lego в The Lego Movie — несмотря на то, что love упоминается там намного чаще.
| Movie | Matched Term | DF | TF | TF × IDF (TF / DF) |
|---|---|---|---|---|
| Sleepless in Seattle | love | 100 | 10 | 10 / 100 = 0.1 |
| The Lego Movie | lego | 1 | 3 | 3 / 1 = 3.0 |
Идея, лежащая в основе TF × IDF, соответствует интуитивному восприятию пользователей того, какие совпадения следует считать важными терминами в тексте.
Пользователи воспринимают редкие слова (например, lego) как гораздо более специфичные и целевые, чем частые (например, love).
Кроме того, если в отрывке текста термин встречается пропорционально чаще, чем в других текстах (то есть TF растёт), то тем более вероятно, что этот текст действительно о данном термине.
Хотя эта модель в целом полезна, можно привести примеры, когда интуиция не срабатывает.
Иногда высокий TF не отражает восприятие пользователем важности термина. Например, высокая частота вхождения термина в коротких текстах, таких как названия фильмов (Fire with Fire), часто не совпадает с представлением пользователя о «большом весе термина».
К счастью, Elasticsearch позволяет отключать TF, когда это необходимо.
Ложь, наглая ложь и similarity
Хотя TF × IDF выглядит как интуитивно понятная формула для взвешивания, на практике сырые статистики требуют дополнительной настройки, чтобы быть действительно эффективными.
Исследования в области информационного поиска показывают: если поисковый термин встречается в тексте в 10 раз чаще, это не означает, что он в 10 раз более релевантен.
Да, большее количество упоминаний действительно коррелирует с релевантностью,
но эта зависимость нелинейна.
Именно поэтому Lucene ослабляет влияние TF и IDF путём применения специального класса similarity.
Классическая Similarity в Lucene снижает влияние tf и idf следующим образом:
-
TF Weight:
sqrt(tf) -
IDF Weight:
log(numDocs / (df + 1)) + 1
| Raw TF | TF Weight | Raw DF | IDF Weight (для 1,000 документов) |
|---|---|---|---|
| 1 | 1 | 1 | 7.215 |
| 2 | 1,414 | 2 | 6.809 |
| 5 | 2,236 | 10 | 5.510 |
| 15 | 3,872 | 50 | 2.976 |
| 50 | 7,071 | 1000 | 0.999 |
| 1000 | 31,623 |
Кроме того, одного лишь ослабления TF × IDF часто недостаточно.
Частоту термина (TF) часто нужно рассматривать относительно общего количества слов в поле, в котором найдено совпадение.
Например:
имеет ли одно упоминание слова alien в книге на 1000 страниц такой же вес, как одно упоминание alien в трёхстрочном фрагменте?
Очевидно, что короткий фрагмент с единственным совпадением
гораздо более релевантен, чем огромная книга с таким же количеством упоминаний.
Именно поэтому в формуле fieldWeight (рассмотренной ранее) результат TF × IDF ещё умножается на fieldNorm — коэффициент нормализации, зависящий от длины поля (или документа).
Формула для fieldNorm выглядит так:
fieldNorm = 1 / sqrt(fieldLength)
Эта нормализация регулирует влияние TF и IDF на вес термина, отдавая приоритет совпадениям в более коротких полях.
Нормы (norms) рассчитываются на этапе индексирования и занимают место в индексе.
Кроме того, в зависимости от особенностей приложения и поведения пользователей,
они не всегда отражают реальное восприятие важности термина в тексте.
К счастью, Lucene позволяет полностью отключить нормализацию (norms) при необходимости.
В совокупности, классическая similarity в Lucene вычисляет вес термина по формуле:
TF_weighted × IDF_weighted × fieldNorm
Обратимся снова к примеру из расчёта fieldWeight, и ты увидишь, как это выглядит на практике:
0.4414702, fieldWeight in 31, product of:
1.4142135, tf(freq=2.0), with freq of:
2.0, termFreq=2.0
3.9957323, idf(docFreq=1, maxDocs=40)
0.078125, fieldNorm(doc=31)
Учет важности поискового термина
Вычисление веса запроса (queryWeight) не подчиняется той же формуле, что и вес термина в документе.
-
В большинстве случаев многократное повторение термина в запросе
не означает, что этот термин более важен. (Пользователи почти всегда вводят термин только один раз.) -
Кроме того, запросы обычно очень короткие, поэтому дополнительная нормализация по длине запроса не требуется — она просто опускается.
Таким образом, в queryWeight от предыдущей формулы остаётся только IDF.
Дополнительно, queryWeight включает два других фактора:
-
Повышение значимости (boosting) на этапе выполнения запроса
-
Нормализация запроса (queryNorm)
Сначала разберёмся с queryNorm. Первое, что важно: если нет boosting-а, queryNorm не имеет значения — она остаётся постоянной для всех совпадений в одном запросе.
Она была задумана как способ сделать оценки сопоставимыми между разными результатами одного поиска. Но на практике она с этим плохо справляется.
Никогда не следует пытаться сравнивать оценки релевантности между запросами или полями, так как статистики вроде IDF и TF слишком сильно различаются.
Кстати, в обсуждениях Lucene часто поднимается вопрос об исключении этого коэффициента.
Что действительно важно в queryWeight — это коэффициент boost. В нашем запросе нет boosting-а для поля overview, но есть boost для совпадений в title.
К сожалению, иногда эффект от boost снижается из-за queryNorm. Если сравнить queryNorm для совпадения в title (Alien) с queryNorm в поле overview, можно заметить, что значения различаются примерно в 10 раз.
Исправление ранжирования Space Jam против Alien
Теперь, вооружившись полным пониманием механики подсчёта оценок в Lucene,
можно сравнить объяснения (explain) для Space Jam и Alien.
У фильма Alien два совпадения:
-
сильное совпадение в поле title,
-
и намного более слабое совпадение в поле overview.
У Space Jam два совпадения, оба в поле overview.
Если внимательно посмотреть, что именно влияет на различия в оценках совпадений,
становится видно: оценки совпадений для поля overview почти всегда значительно слабее,
чем для поля title.
Можно увидеть это на примере высокого веса совпадения для title в Alien:
3.1940954, weight(title:alien in 223)
по сравнению с гораздо более низкой оценкой для совпадения alien в overview:
0.03975798, weight(overview:alien in 1289)
Эта разница примерно на два порядка! (то есть примерно в 100 раз)
Подожди, ведь мы явно указывали поисковику, что title должен быть всего лишь в 10 раз важнее overview через boosting, верно?
Да, мы действительно применили boost.
Однако теперь мы знаем, что оценки между разными полями вообще нельзя напрямую сравнивать.
Они существуют в совершенно отдельных “вселенных” оценивания.
Сравнивая совпадение в title для Alien с совпадением в overview для alien, можно увидеть это очень наглядно.
3.1940954, weight(title:alien in 223) [PerFieldSimilarity], result of:
3.1940954, score(doc=223, freq=1.0 = termFreq=1.0), product of:
b IDF is significantly lower for “alien” in overview, overview is also longer, giving it a higher field norm.
0.4793558, queryWeight, product of:
6.6633077, idf(docFreq=9, maxDocs=2881)
0.07193962, queryNorm
6.6633077, fieldWeight in 223, product of:
1.0, tf(freq=1.0), with freq of:
1.0, termFreq=1.0
6.6633077, idf(docFreq=9, maxDocs=2881)
1.0, fieldNorm(doc=223)
0.03975798, weight(overview:alien in 1289) [PerFieldSimilarity], result of:
0.03975798, score(doc=1289, freq=1.0 = termFreq=1.0), product of:
0.03382846, queryWeight, product of:
4.701128, idf(docFreq=70, maxDocs=2875)
0.0071958173, queryNorm
1.175282, fieldWeight in 1289, product of:
1.0, tf(freq=1.0), with freq of:
1.0, termFreq=1.0
4.701128, idf(docFreq=70, maxDocs=2875)
0.25, fieldNorm(doc=1289)
Здесь видно, что именно влияет на различие в значениях fieldWeight у двух совпадений.
Эти поля по своей природе сильно отличаются: overview обычно представляет собой текст длиной в абзац, в то время как title — это всего несколько слов.
Из-за этого значения fieldNorm для этих полей получаются очень разными.
Кроме того, распределение терминов в полях overview не совпадает с распределением терминов в полях title.
Эти особенности часто связаны с тем, как именно авторы формулировали содержание полей.
-
Что думают маркетологи фильмов, когда пишут overview?
-
Какие слова они выбирают?
-
Насколько кратко или подробно они пишут?
-
Как киностудии выбирают названия фильмов?
-
Используют ли они существующие бренды (и знакомые термины)
или стараются быть оригинальными?
Работа с релевантностью текста требует понимать как:
-
логику автора (почему он выбрал такие формулировки),
-
так и намерения пользователя (почему он использует определённые поисковые термины).
Что это значит для расчётов:
Хорошая оценка релевантности в overview может быть значительно ниже, чем хорошая оценка в title.
Boost в 10 раз не означает, что поисковик воспримет поле в 10 раз важнее —
он просто умножает на коэффициент.
Когда начинаешь разбирать механизм совпадений, становится видно: оценки для overview почти всегда заметно ниже, чем для title.
Как правильно использовать веса полей:
Прежде чем применять коэффициенты boost, нужно изучить характерные масштабы оценок по каждому полю.
Может оказаться, что правильнее увеличить вес title всего на 0.1, и этого уже будет достаточно, чтобы совпадения в title были значительно сильнее совпадений в overview —
просто за счёт специфики самих полей.
Давайте перезапустим наш запрос с более разумным boost для title
и посмотрим на результат.
| Num | Relevance Score | Movie Title |
|---|---|---|
| 1 | 1.0016364 | Space Jam |
| 2 | 0.29594672 | Grown Ups |
| 3 | 0.28491083 | Speed Racer |
| 4 | 0.28491083 | The Flintstones |
| 5 | 0.2536686 | White Men Can’t Jump |
| 6 | 0.2536686 | Coach Carter |
| 7 | 0.21968345 | Semi-Pro |
| 8 | 0.20324169 | The Thing |
| 9 | 0.1724563 | Meet Dave |
| 10 | 0.16911241 | Teen Wolf |
Отлично!
Решено? Наша работа никогда не заканчивается!
На самом деле осталось несколько важных моментов для улучшения.
((title:basketbal title:cartoon title:alien)^10.0) | (overview:basketbal overview:cartoon overview:alien)
Помниnt, что символ | означает, что будет взято максимальное значение между оценками двух полей? Повысив веса overview и title более осознанно, мы сделали возможным, что в некоторых случаях overview может обогнать title, когда при сравнении полей берётся максимум.
Но почему вообще используется взятие максимума? Почему именно эта стратегия применяется по умолчанию? Могли бы существовать другие способы объединения оценок, чтобы это не было “или всё, или ничего” между сильным совпадением в title и сильным совпадением в overview?
Возможно, мы решили проблему для Space Jam, но что будет при других поисках?
Когда появятся другие комбинации оценок — не вернёмся ли мы обратно к исходной проблеме?
Кроме того, стоит задать себе ещё один вопрос: можно ли улучшить саму формулу fieldWeight?
-
Действительно ли нам важно учитывать fieldNorm?
-
Нужно ли в этом случае специально отдавать приоритет коротким или длинным текстам?
И, наконец, извечная борьба инженера релевантности: правильно ли сами термины отражают скрытые особенности текста?
Если взять фрагмент из Space Jam:
Michael Jordan соглашается помочь Луни Тунс сыграть в баскетбол против инопланетных рабовладельцев, чтобы выиграть свою свободу.
Можно задать себе несколько вопросов:
-
Все ли важные особенности реально зафиксированы в объяснении?
-
Мы не видели совпадений по слову cartoon;
должны ли слова toons или Looney Toons соответствовать cartoon? -
А как насчёт Michael Jordan?
Мы, люди, автоматически ассоциируем его с баскетболом;
должны ли мы усиливать вес термина basketball при наличии имени Jordan?