К сожалению, существует интуитивно распространенное мнение, что ETL c графическим интерфейсом имеет неоспоримые преимущества. Реальность, как обычно, гораздо сложнее и не всегда ответ может быть односложным.
Чтобы разобраться в проблеме, разделим все проекты по построению хранилища данных и отчетности на два вида:
| Критерий | Нативное хранилище данных | Комплексное хранилище данных |
|---|---|---|
| Ландшафт | В IT ландшафте, как правило, одна крупная система в которой сосредоточено большинство процессов Компании | В IT ландшафте десятки и сотни систем |
| Бизне-процесс | Бизнес-процессы начинаются и заканчиваются в одной и тоже IT системе | Бизнес-процесс протекает среди нескольких систем, имея начало в одной и конец в другой |
| Стейкхолдеры | Одна группа стейкхолждеров с непротиворечивыми требованиями | Многочисленные группы стейкхолдеров, требования которых могут быть в консонансе |
| Команда | Небольшая команда, отстутствие активной работы HR, отсутствие DevOps практик, нечеткое выделение ролей и процессов в команде | Большая команда, активная ротация и работа HR, активное применение DevOps практик, строгое разделение на роли и процессы |
| Потоки данных | Данные в режиме реального времени отсутствуют | Часть данных передается и обрабатывается в режиме реального времени |
| Документация | Ведется на верхнем уровне, нет высокой потребности в детализации | Требуется детальная документация |
| Развитие | Стабильная компания, не предполагающая крупных изменений | Активно развивающаяся компания на быстро меняющимся рынке, с постоянной потребностью рефакторинга |
| Деление на среды | Не используется | Активно используется |
| Количество артефактов | Небольшое количество баз данных, таблиц, витрин, пользователей. Простая ролевая модель | Большое количество баз данных, доменов, таблиц, пользователей. Сложная ролевая модель |
| Цифровизация внутренних процессов хранилища данных | В виду небольшой команды и малого количества артефактов не используется | В виду большой команды, большого количества стейкходеров активно используется цифровизация процессов, которая позволяет получить метрики производительности команды и управлять множеством проектов в параллель |
| Качество данных | Хорошее, проблемы в основном на уровне технического качества данных | Низкое, большое количество проблем, как на техническом так и на бизнес уровне. Требуется проверка качества данных после каждой транфсформации |
| Нестандартные сценарии | Не требутся | Есть задачи, которые тяжело решаются с помощью стандартного инструментария |
Исходя из такого деления можно выделить случай, где использование Low-Code ETL не вызывает никаких вопросов. Это случай с нативным хранилищем данных, где размер и компетенции команды не позволяют развернуть управлением хранилищем через код. И это и не требуется, так как в виду простоты ландшафта и стоящих перед командой задач, подобная попытка приведет к падению T2M без явных преимуществ.
Для комплексного хранилища данных ответ не очевиден. Но в большинстве случаев, low code платформа может не оказать влияние на T2M, а в некоторых случаях может снизить его при некорректном внедрении. Почему это может произойти?
Необходимо тщательно рассматривать каждую low-code платформу на возможность организации высокопроизводительного труда в ней. Все нюансы всплывают именно на организации работ в большой команде, с множеством параллельных процессов, когда результат действий одной группы ролей оказывает воздействие на другую группу :
- Каким образом и на каких этапах вы организуете review изменений?
- Каким образом у вас происходить перенос из тестовой среды в производственную?
- Каким образом вы будете отслеживать изменение объектов?
- Каким образом вы будете обеспечивать версионность объектов?
- Каким образом вы будете препятствовать изменению объекта если от него зависят другие объекты?
- Каким образом вы будете собирать метрики производительности с команды?
- Каким образом вы будете проводить однотипный рефакторинг на нескольких сотнях таблиц?
- Каким образом вы обеспечите параллельную работу группы людей над одним пайплайном, так чтобы они двигались по нему с двух сторон: одна группа от источников к DDS, вторая группа от визуализации к DDS?
- Каким образом вы сможете обеспечить откат последних изменений?
- Каким образом вы привяжете работу команды к задачам в трекере?
и так далее.
Даже самодокументирование за счет визуализации в GUI на больших количествах объектов может превратиться из преимущества в недостаток (см. скриншот из GUI)
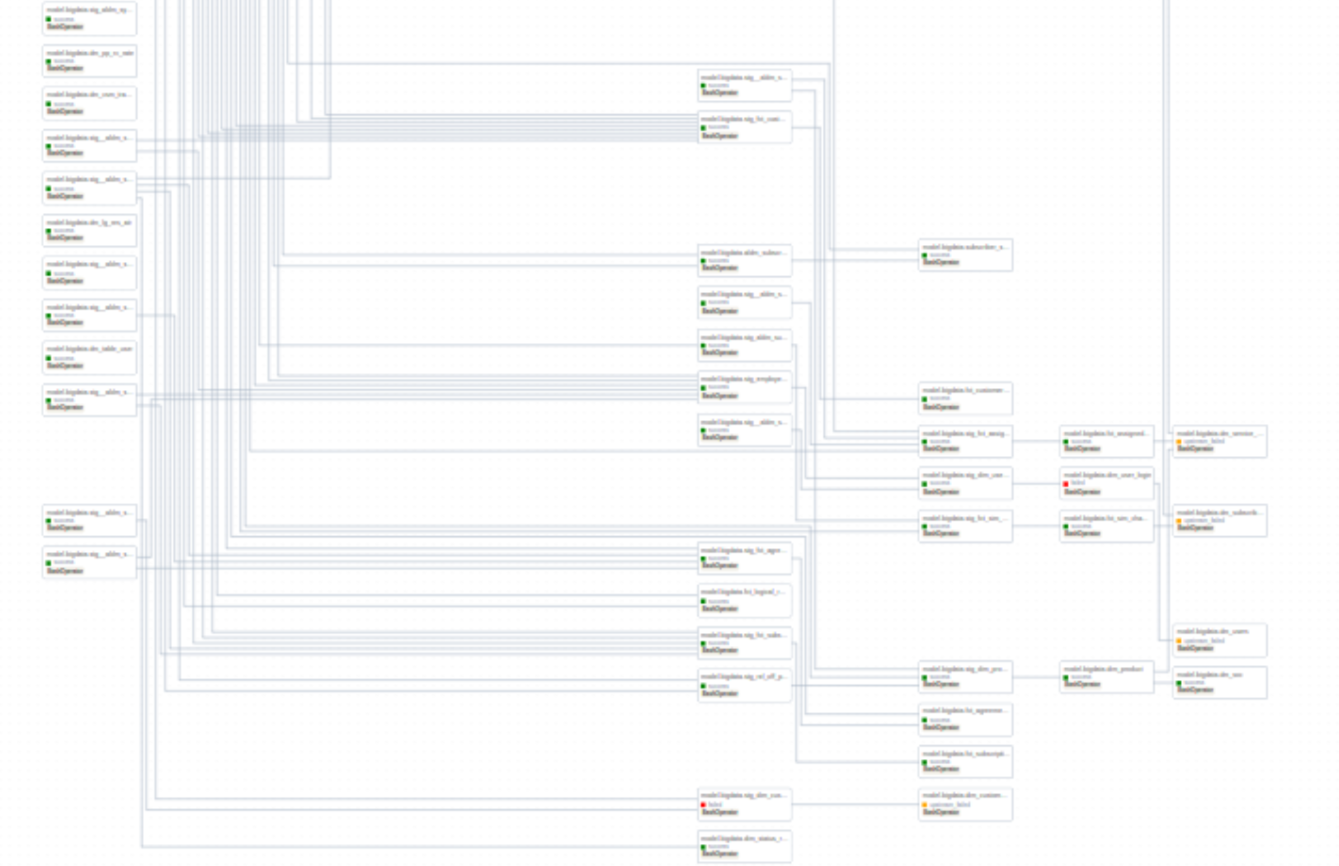
Если вы без проблем можете ответить на большинство предыдущих вопросов, то это означает, что вы знаете, что вы делаете и что вас ждет в эксплуатации. Если же вы постоянно при ответах оперируете сторонними продуктами (например, excel/jira), то это может означать, что вы не используете корректно low-code платформу с точки зрения организации высокопроизводительных процессов в команде.
Чтобы продвинуться дальше, нам потребуется разделить термин ETL на две части. Первая часть EL - будет у нас отвечать за Извлечение/Загрузку данных, а вторая T - за трансформацию. Это устойчивая практика при построении современного комплексного хранилища данных, когда вы сначала перемещаете данные as-is, без трансформаций на лету, и только после размещения сырых данных вы начинаете заниматься вопросами их преобразования.
EL - здесь выглядит, как крайне однотипная повторяющаяся работа, которая легко, сама по себе может делаться в параллель. Она не требует глубокого анализа, документирования и так далее. Это максимально простая работа, которая может и должна вестись с применением инструментов автоматизации. В качестве такого инструмента могут использоваться low code платформы, которые окажут на этом участке сильное положительное влияние на T2M.
Вернемся к T - трансформациям. Типичный кейс работы аналитика при трансформации данных это использование SQL. Вам не удастся увидеть на практике аналитика, который сразу строит трансформацию с помощью GUI (если речь не идет о работе в нативном хранилище данных). Аналитик не знает с какими данными он работает, ему требуется провести профилирование исходных данных, просмотреть каждую используемую колонку глазами, убедиться контрольными sql запросами, что после каждой операции join он не потерял данные. На практике всю эту работу они проделывают с помощью sql, а не с помощью инструментов визуализации.
В итоге, спустя некоторое время, он получает запрос для трансформации данных. В наилучшем сценарии - low code платформа позволит аналитику скопировать готовый работающий код и платформа будет заниматься его исполнением (а тогда зачем она?), в наихудшем сценарии, он вынужден будет произвести работу по разбитию своего sql запроса на требуемые инструментом блоки визуализации. Может ли он совершить ошибку на этом этапе? Проделывает ли он работу дважды? Ответы оставим за скобками.
Современное сообщество “трансформаторов данных” учло весь предыдущий опыт и создало один из самых популярных на текущий момент инструментов трансформации данных dbt. Инструмент тесно интегрирован с git, позволяет вести многопользовательскую работу аналитикам, использует привычный им синтаксис sql, позволяет переиспользовать кусочки sql, написанные ранее в вашей команде. Низкий порог входа, проведение ревью, возможность гибко организовывать привязку коммитов к процессам, версионирование, поддержка сред, встроенные инструменты тестирования, которые выполняют роль защиты - все это и многое другое сделало dbt очень популярным инструментом.
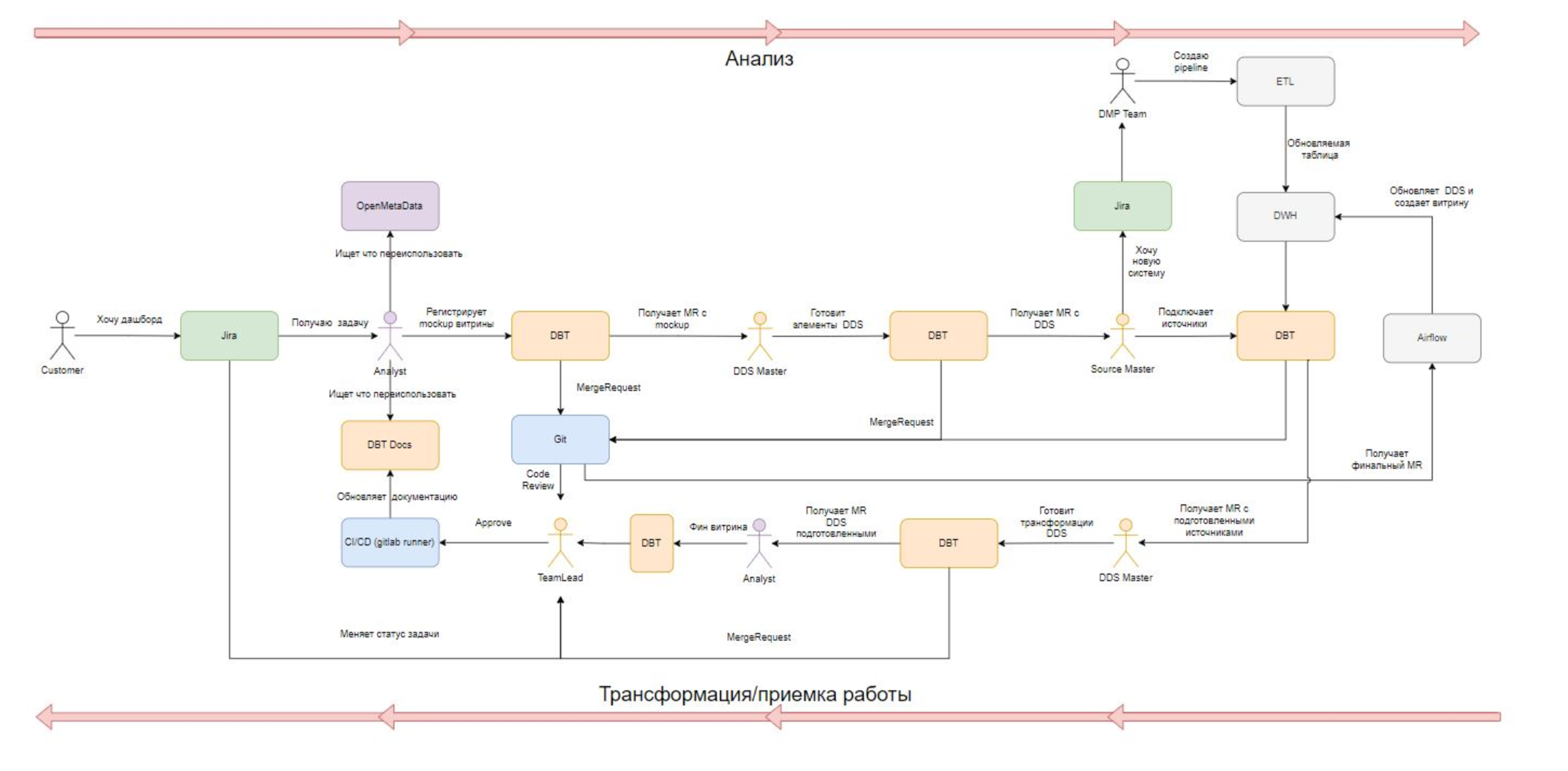
Является ли он low-code платформой? Нет. Имеет ли он GUI - да!
gif:
static:
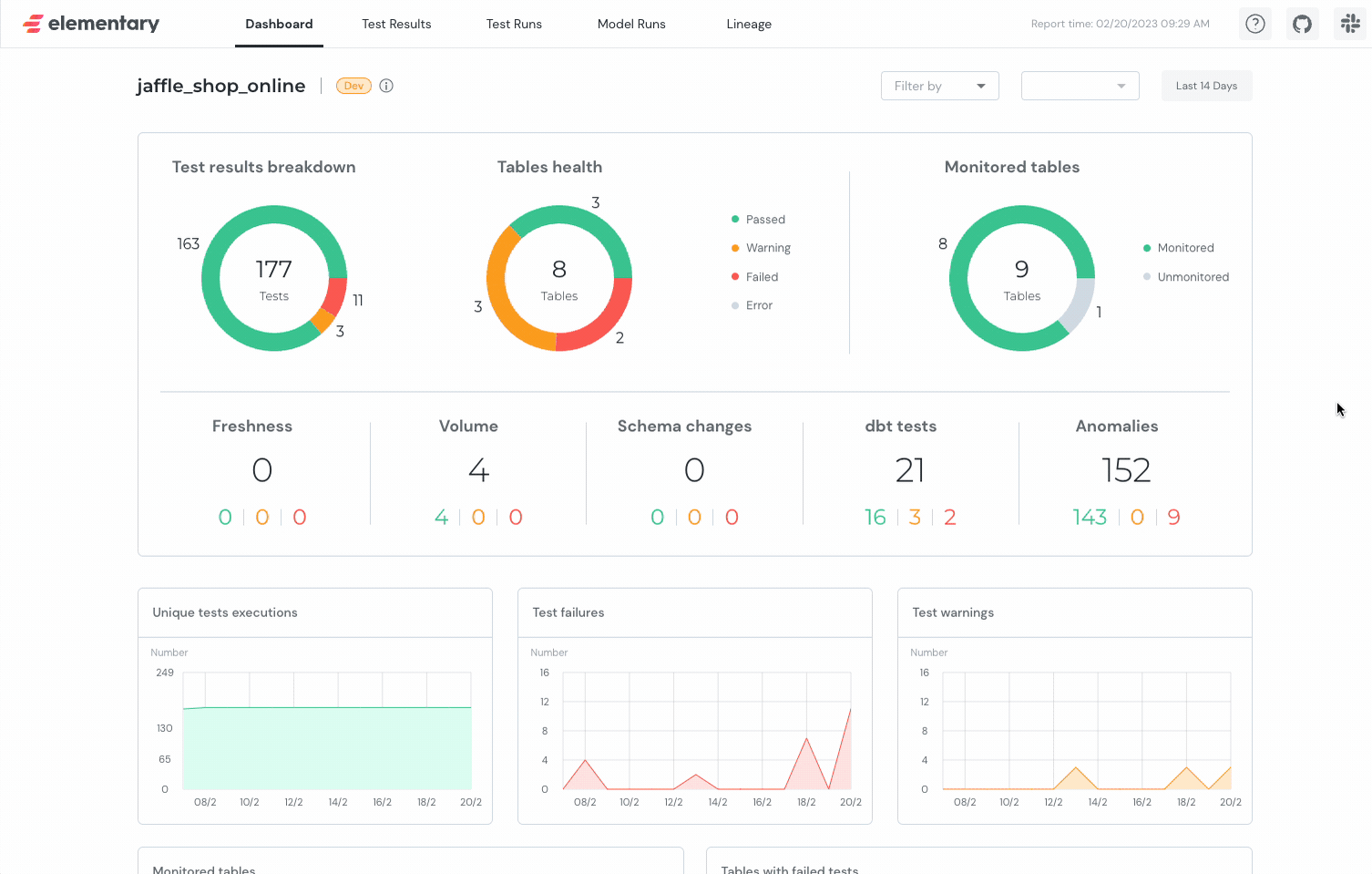
dbt не является инструментом для EL операций, но позволяет высокопроизводительным и комфортным образом решать задачу по трансформации данных в условиях большой команды и множества параллельных процессов.
Таким образом, при построении современного комплексного хранилища данных имеет смысл выделять две группы процессов: EL и T и выбирать инструменты для управления этими группами процессов отдельно. В случае нативного хранилища данных такое разделение не имеет смысла и их необходимо рассматривать как единый процесс ETL