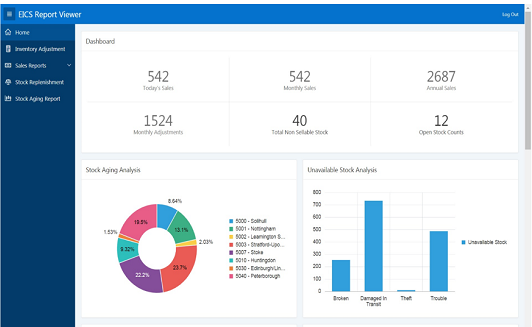
Цифровая трансформация
Бизнес клиент представляет собой сетевой ритейл в подготовительной фазе к цифровой трансформации, итогом которой должно стать:
- Переход на современную учетную систему
- Развитие цифровых каналов сбыта
- Оцифрованные бизнес-процессы, контролируемые через показатели эффективности
- Использование продвинутых методов аналитики данных для корректировки стратегии бизнеса и перехода к концептам Revenue Management/Product Recommendation и т.д.
- Минимизация ручных процессов/повышение эффективности труда
Основой цифровой трансформации должен стать блок Управление данными, с помощью которого можно подготовить переход компании на цифровые рельсы. Именно этот блок занимает центральное место с точки зрения получения всех цифровых данных в компании, а значит трансформация этого блока позволит лучше подготовиться к изменениям в основном бизнес-процессе компании в момент перехода на новую ERP. Кроме того, успешный рефакторинг “Управления данными” создаст востребованный механизм аудита проводимых трансформации бизнеса, как во время исполнения работ так и в повседневной операционной деятельности после завершения проектов.
Исходная позиция
На текущий момент ландшафт управления данными можно представить следующим образом:
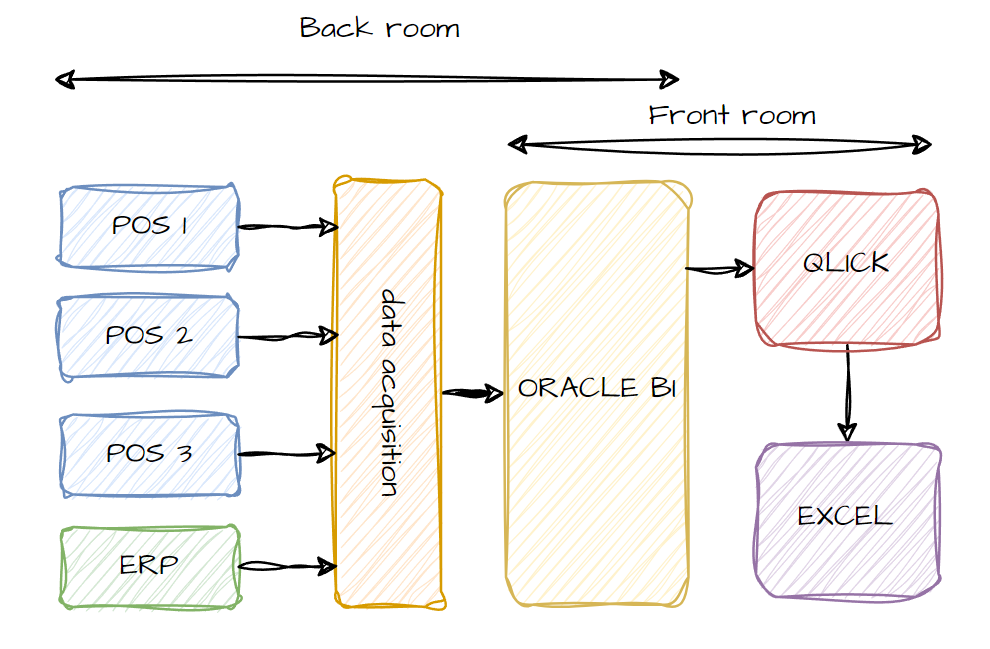
Со множества точек продаж, каждую из которых в технологическом плане можно рассмотреть как отдельную базу данных - детальные данные собираются в центральное хранилище данных на базе Oracle. Сюда же поступают данные из основной учетной системы (ERP). Далее эти данные передаются в BI систему QlickView, откуда во множестве случаев сотрудники выгружают данные в Excel для решения своих операционных задач.
Данная архитектура сложилась естественным эволюционным путем при решении ежедневных задач и не учитывала стратегию компании в долгосрочном плане. В итоге архитектура приобрела следующие недостатки:
- Отсутствие гибкости при изменении технологического ландшафта компании. Переход на новую ERP приведет к масштабному рефакторингу хранилища данных, как и появление/изменение любой крупной учетной системы в ландшафте компании
- Низкая производительность основного слоя хранения данных ORACLE BI
- Сложность/невозможность создания слоя для продвинутой аналитики
- Низкое качество данных в виду отсутствия ряда технологических компонентов для управления данными
- Отсутствие документации
- Низкая прозрачность данных в компании (какие данные, кто использует, как часто, в каких бизнес-процессах)
- Устаревший и неподдерживаемый компонент QlickView с ограниченным количеством лицензии (100) без возможности их увеличить.
- Большое количество shadow system (excel), с помощью которых сотрудники компенсируют функциональные и технологические разрывы.
- Сложность/невозможность создания слоя для аналитики данных в режиме реального времени
Вывод
В текущем положении хранилище данных компании не может стать основой для цифровой трансформации и должно быть подвергнуто глубокому рефакторингу с пересмотром своей концепции.
Предлагаемое решение
Функциональные требования
Функциональные требования к новой платформе данных могут быть схематично отображены следующим образом:
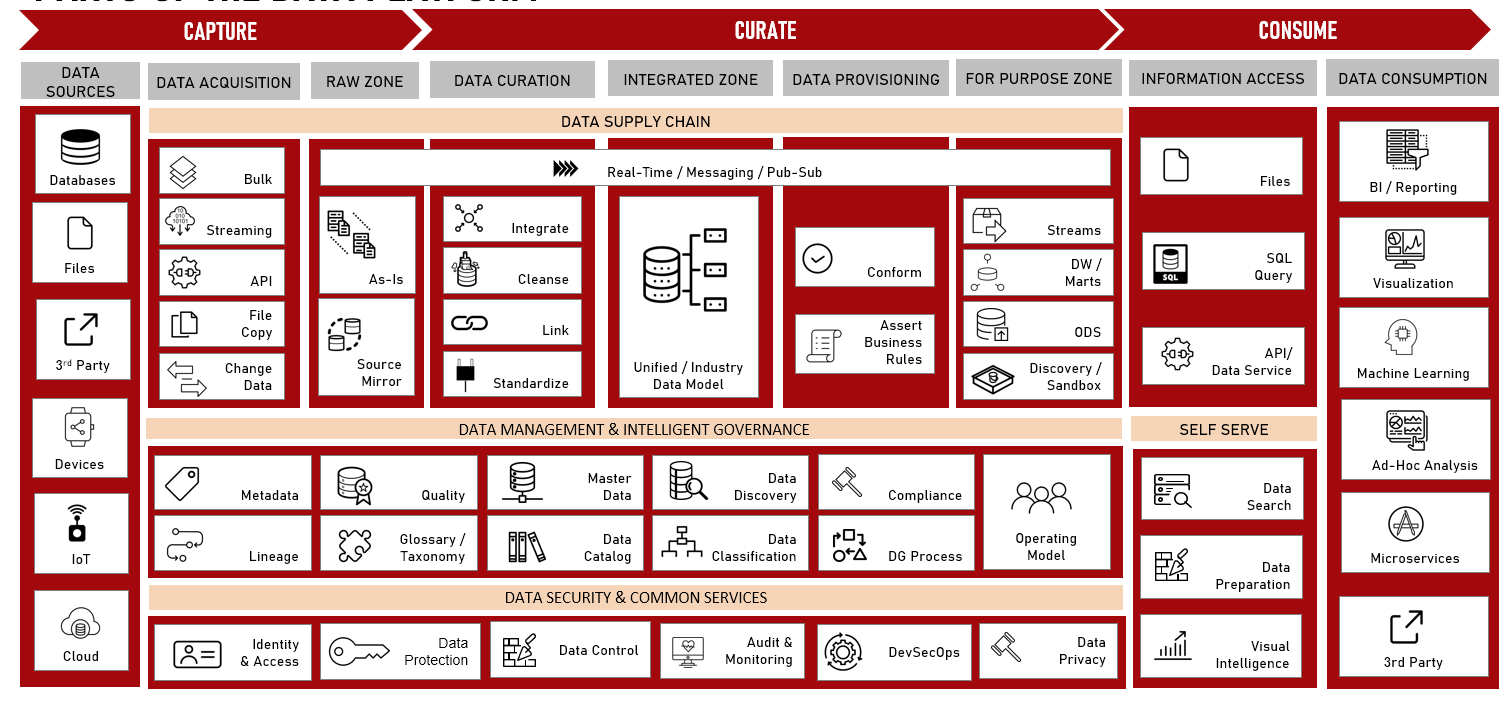
| Функциональный домен | Функциональный блок | Краткое описание |
|---|---|---|
| Источники данных | Базы данных | Платформа должна поддерживать подключение к данному типу источника данных |
| Файлы в формате csv, excel, xml | ||
| API внешних систем и облачных сервисов | ||
| Цифровые устройства и IOT | ||
| Методы загрузки данных | Загрузка данных пачкой | Платформа должна поддерживать метод загрузки данных |
| Загрузка данных в режиме реального времени | ||
| Поддержка технологии CDC | ||
| Загрузка данных из файлов | ||
| Сырой слой | Платформа должна иметь слой для хранения данных as-is перед их дальнейшей обработкой | |
| Слой должен представлять из себя распределенное файловое хранилище как наиболее экономически эффективное решение | ||
| Слой должен стать основой для работы с инструментами продвинутой аналитики и машинным обучением | ||
| Обработка данных | Интеграция данных | Платформа должна поддерживать основные методы для технической обработки данных, позволяя получать непротиворечивые целостные данные |
| Очистка данных | ||
| Линковка данных | ||
| Стандартизация данных | ||
| Индустриальная модель данных | Платформа должна позволять проектировать и использовать в работе промышленную модель данных бизнеса, которая будет независима от технологического ландшафта компании | |
| Бизнес-правила | Платформа должна поддерживать методы организации проверки бизнес-качества данных путем проверки различных бизнес-сценариев | |
| Слои хранения данных | ODS | Платформа должна поддерживать возможность организовывать различные слои данных с разными сценариями потребления данных |
| Стриминг | ||
| Песочница | ||
| Витрины данных | ||
| Доступ к данным | SQL | Платформа должна поддерживать следующие интерфейсы для получения данных |
| Выгрузка в файлы | ||
| API | ||
| Управление и надзор | Управление метаданными | Платформа должна иметь следующие подсистемы и возможность организовать перечисленные процессы |
| Линедж данных | ||
| Мониторинг качества данных | ||
| Общий глоссарий по данным и платформе | ||
| Управление мастер-данными/интеграция с MDM | ||
| Каталог данных | ||
| Классификация данных | ||
| Управление внутренними процессами платформы данных | ||
| Операционная модель взаимодействия между сотрудниками платформы данных и с сотрудниками других подразделений | ||
| Безопасность | Контроль доступа к платформе | Платформа должна иметь следующие подсистемы и процессы для защиты данных |
| Защита данных | ||
| Аудит и мониторинг использования данных | ||
| DevSecOps | ||
| Самообслуживание | Поиск данных | Платформа должна предоставлять пользователям возможность самостоятельной работы по следующим процессам |
| Подготовка данных | ||
| Визуализация данных | ||
| Потребление данных | Отчеты | Платформа должна обеспечивать следующие виды потребления данных |
| Визуализация данных | ||
| Предоставление данных моделям машинного обучения | ||
| Ad-hoc анализ | ||
| Предоставление данных внутренним микросервисам и учетным системам | ||
| Предоставление данных третьей стороне |
Так же конечное потребление данных может быть представлено в виде типов запросов:
Отчетные запросы
Эти запросы отражают «отчетную» природу системы принятия решений. Они включают запросы, которые выполняются периодически для ответа на известные, предопределенные вопросы о финансовом и операционном здоровье бизнеса. Хотя отчетные запросы, как правило, статичны, незначительные изменения являются обычным явлением. От одного использования отчетного запроса к другому пользователь может сместить фокус, изменив диапазон дат, географическое местоположение или название бренда.
Ad hoc запросы
Эти запросы отражают динамическую природу системы принятия решений, в которой импровизированные запросы создаются для ответа на немедленные и конкретные бизнес-вопросы. Основное различие между запросами ad hoc и отчетными запросами заключается в ограниченной возможности архитекторов системы прогнозировать такие запросы, а значит структуры данных могут быть неоптимальны для выполнения конкретного ad hoc запроса.
Итеративные OLAP запросы
OLAP запросы позволяют исследовать и анализировать бизнес-данные для обнаружения новых и значимых взаимосвязей и тенденций. Хотя этот класс запросов похож на класс «Ad hoc», он отличается пользовательским сценарием, в котором отправляется последовательность запросов, где результат прошлого запроса может использоваться для подачи на вход следующего запроса. Такая последовательность может включать как сложные, так и простые запросы. Например, это может быть сценарий drill down (углубление в данные)
Запросы Data mining
Data mining - это процесс просеивания больших объемов данных для создания связей между содержанием данных. Он может предсказывать будущие тенденции и поведение, позволяя компаниям принимать проактивные решения на основе знаний. Этот класс запросов обычно состоит из объединений и больших агрегаций, которые возвращают большие наборы данных.
Нефункциональные требования
Пример нефункциональных требований к платформе данных, которые должны быть скорректированы и расширены в ходе выполнения проекта. Этот шаблон так же должен применяться для выбора каждого отдельного компонента
| # | Requirement type | Тип требования | Требования |
|---|---|---|---|
| 1 | Accessibility | Доступность | Отдельные компоненты системы должны быть легко доступны: 1) через браузер (дата аналитики, дата инженеры, пользователи) 2) через мобильный браузер (пользователи) 3) excel (пользователи) |
| 2 | Adaptability | Приспособляемость | Вендор должен иметь прозрачную политику по доработке продукта под потребности пользователя, понятную систему приоритетов по выбору разрабатываемого функционала или предоставлять это как отдельную услугу |
| 3 | Auditability and control | Проверяемость и контроль | Продукт должен иметь систему логов из которой аудитору было бы понятно КТО сделал ЧТО и КОГДА это произошло |
| 4 | Availability (SLA) | Доступность (SLA) | Вендор должен предложить рекоммендуемый SLA в случае если система полностью эксплуатируется на стороне Заказчика с учетом различных регламентных работ, работ по обновлению продукта. В случае, если используются облачные компоненты - для них должен указываться гарантированный SLA |
| 5 | Backup | Резервное копирование | Система должна поддерживать возможность резервного копирования в ходе которого бы резервировались метаданные (пользователи, настройки потоков данных, шаблоны дашбордов и т.д.), для таблиц должна существовать процедура их резервного копирования при необходимости |
| 6 | Boot up time | Время загрузки | Время полного включения системы(всех компонентов) не должно превышать X мин |
| 7 | Capacity, current and forecast | Мощность, текущая и прогнозируемая | Вендор должен предоставить механизмы расчета(формулы/калькуляторы) ресурсов используемых системой в зависимости от первоначальных параметров, таким образом, чтобы можно было рассчитать необходимые ресурсы (процессоры, память, диски и т.д.) на 3 года вперед |
| 8 | Certification | Сертификация | В случае Open Source компонентов должен существовать публичный незаброшенный проект с широким коммьюнити |
| 9 | Compliance | Комплаенс | Вендор должен быть более 5 лет на рынке, иметь опыт внедрения своего Продукта, не иметь налоговых задолжностей и судебных дел |
| 10 | Configuration management | Управление конфигурациями | Продукт должен поддерживать версионирование конфигурации, возможность работать с разделением на среды |
| 11 | Conformance | Соответствие | Поддержка общепринятых методологий построения платформ данных: Data Vault/Star schema/Snowflake/Anchor и общеупотребимых терминов, сокращений в нейминге |
| 12 | Cost, initial and Life-cycle cost | Стоимость, первоначальная и стоимость жизненного цикла | Вендор должен иметь возможность предоставить методологию расчета стоимости владения в зависимости от первоначальных параметров |
| 13 | Data integrity | Целостность данных | Продукт должен иметь возможность проводить процедуру реконсиляции данных и не допускать расхождения ссылочной целостности на пользовательском слое |
| 14 | Data retention | Хранение данных | Продукт должен иметь возможность хранить исторические данные на экономически эффективных средствах хранения с возможностью поднять эти данные в операционный слой |
| 15 | Dependency on other parties | Зависимость от других сторон | Вендор должен подтвердить независимость разработки от зависимых библиотек, или оценку рисков если такие библиотеки/технологии используются |
| 16 | Deployment | Развертывание | Продукт должен иметь мастер развертывания или документацию для самостоятельного развертывания в on-prem/cloud/hybrid вариантах |
| 17 | Development environment | Среда разработки | Продукт должен поддерживать среду разработки, таким образом, чтобы третья сторона могла проводить работы без доступа к данным. Продукт должен иметь процесс автоматической миграции разработанных потоков данных со среды разработки на тестовую среду и непосредственно в промышленную эксплуатацию |
| 18 | Disaster recovery | Аварийное восстановление | Продукт должен поддерживать процесс (иметь регламент) при помощи которого Компания может предвидеть и устранять аварии, связанные с технологией |
| 19 | Documentation | Документация | Документация должна быть в публичном доступе, обновляться после каждого релиза, содержать общие архитектурные принципы продукта, типовые кейсы использования, лучшие практики, часто задаваемые вопросы и типовые проблемы |
| 20 | Durability | Прочность | Данные должны оставаться неповрежденными, несмотря на выход из строя отдельных компонентов инфраструктуры |
| 21 | Efficiency (resource consumption for given load) | Эффективность (потребление ресурсов при заданной нагрузке) | Система не должна отказывать в обслуживании пользователю при дефиците ресурсов |
| 22 | Elasticity | Эластичность | Продукт должен иметь возможность гибко масштабироваться без down-time, масштабирование не должно приводить к перекосу данных в кластере и неэффективной работе после масштабирования |
| 23 | Emotional factors | Эмоциональные факторы | Интерфейс должен быть дружелюбен по отношению к пользователю и позволять интуитивно выполнять работу |
| 24 | Extensibility (adding features, and carry-forward of customizations at next major version upgrade) | Расширяемость (добавление функций и перенос настроек при следующем обновлении основной версии) | Обновление продукта должно происходить без down time или с заранее оговоренным минимальным down time. Релизы должны тестироваться на стороне Вендора и не должны приводить к потере существующего функционала |
| 25 | Failure management | Управление отказами | Система должна оповещать при отклонении одного из компонентов от рабочих характеристик |
| 26 | Flexibility (e.g. to deal with future changes in requirements) | Гибкость (например, для учета будущих изменений требований) | Инфраструктурная: возможность выбирать между onprem/cloud/hybrid DevOps гибкость: возможность выбирать между doker/k8s; gitlab pipelines/jenkins Гибкость горячего хранения: возможность выбирать хранение данных между Greenplum/Clickhouse и их managed версий Гибкость холодного хранения: возможность выбирать между s3/hdfs Гибкость BI: возможность выбирать или использовать одновременно популярные BI решения |
| 27 | Integrability (e.g. ability to integrate components) | Интегрируемость (например, способность интегрировать компоненты) | Возможность интегрироваться с системами мониторинга компании |
| 28 | Internationalization and localization | Интернационализация и локализация | Пользовательский интерфейс должен быть на ___ языке, интерфейс для разработчиков может быть на английском языке |
| 29 | Interoperability | Взаимодействие | Компоненты внутри продукта должны взаимодействовать без конфликтов, не должны использовать незадокументированные возможности друг друга, коммуникация компонентов должна происходить по стандартным протоколам и форматам |
| 30 | Legal and licensing issues or patent-infringement-avoidability | Правовые и лицензионные вопросы или возможность предотвращения нарушения патентных прав | Не должно быть лицензионного ограничения на количество и тип подключаемых источников, допускается лицензирование по мощности (кол-во ядер, памяти), по кол-ву пользователей |
| 31 | Maintainability (e.g. mean time to repair – MTTR) | Ремонтопригодность (например, среднее время ремонта – MTTR) | MTTR должен быть частью Контракта |
| 32 | Modifiability | Модифицируемость | Вендор должен предоставить Change Log Продукта за последние полгода, иметь его в открытом доступе |
| 33 | Network topology | Топология сети | Вендор должен предоставить рекомендуемую топологию сети, рекомендуемую пропускную способность |
| 34 | Open source | Открытый исходный код | Если Продукт имеет open source компоненты, Вендор должен указать репозитории , которые он использует |
| 35 | Operability | Работоспособность | Продукт должен предоставлять команде эксплуатации средства для наблюдения, прогнозирования, предотвращения и устранения инциндентов |
| 36 | Performance / response time (performance engineering) | Производительность/время отклика | Время сборки хранилища данных с целью доступности их в системе репортинга не должно превышать 3 часов |
| 37 | Platform compatibility | Совместимость с платформами | Вендор должен указать с какими версиями платформ совместим продукт, как быстро происходят патч релизы при обновлении платформ. Какая сторона отвечает за обновление используемых платформ |
| 38 | Privacy (compliance to privacy laws) | Конфиденциальность | Возможность маркировать данные как персональные данные, данные особой важности и т.д. |
| 39 | Portability | Портативность | Продукт должен поддерживать процедуру миграции с одной инфраструктуры на другую |
| 40 | Readability | Удобочитаемость | Должен быть предоставлено рекоммендуемое соглашение о наименований объектов/компопнентов в системе |
| 41 | Reliability (e.g. mean time between/to failures – MTBF/MTTF) | Надежность (например, среднее время между отказами и до отказа – MTBF/MTTF) | MTBF/MTTF должно быть частью Контракта |
| 42 | Reporting | Отчетность | Продукт должен поддерживать внутреннюю отчетность из которой можно было бы понять кол-во и тип подключенных систем, их состояние, кол-во объектов в хранилище данных, кол-во пользователей и их роли, кол-во дашбордов и пользователи имеющие к ним доступ, размер хранилища, точка актуальности данных, кол-во потоков даннных и их состояние. Данные должны быть представлены как в аггрегированном виде (числа) так и в табличном представлении с возможностью выгрузки в текстовый формат |
| 43 | Resilience | Отчетность | Продукт не должен иметь единой точки отказа |
| 44 | Resource constraints (processor speed, memory, disk space, network bandwidth, etc.) | Ограничения ресурсов | Вендор должен указать рекомендуемые параметры используемых ресурсов |
| 45 | Response time | Время отклика | Время отклика интерфейса не должно превышать 3 сек в максимуме, а среднее время отклика не должно превышать 1,5 сек |
| 46 | Reusability | Возможность повторного использования | Продукт должен позволять подключать сторонние ETL/BI инструменты к хранилищу данных |
| 46 | Robustness | Надежность | Несмотря на различные проблемы в компонентах системы/инфраструктуре - система стремится обеспечивать максимальное количество и качество данных на пользовательском слое без пропусков данных |
| 47 | Security | Безопасность | Продукт должен поддерживать аутентификацию/авторизацию. Быть совместимым с keycloack/AD. Поддерживать разделение ролей на уровне ETL процессов, на уровне данных и на уровне визуализации. Поддерживать одну из методологий: RBAC/ABAC/CBAC и т.д. |
| 48 | Scalability (horizontal, vertical) | Масштабируемость (горизонтальная, вертикальная) | Продукт должен поддерживать горизонтальное масштабирование каждого компонента |
| 49 | Supportability | Поддерживаемость | На рынке вакансии должны присутствовать специалисты, которые могут эксплуатировать и поддерживать продукт. Вендор должен предоставлять поддержку. На рынке должны присутствовать другие компании, которые имеют возможность поддерживать продукт |
| 50 | Testability | Тестируемость | Продукт должен иметь механизмы тестирования, помогающие принимать решение о поставке новых или измененных потоков данных в промышленную эксплуатацию с тестовой среды |
| 51 | Throughput | Пропускная способность | Скорость загрузки и обработки данных не должна быть менее 1 млн строк в минуту |
| 52 | Transparency | Прозрачность | Продукт не должен содержать скрытых или незадокументированных компонентов |
| 53 | Usability (human factors) by target user community | Удобство использования (человеческий фактор) целевым сообществом пользователей | Продукт не должен иметь негативных отзывов в открытом доступе |
| 54 | Volume testing | Тестирование на объеме | Продукт должен позволять корректно работать с данными объемом до 10 Тб |
Shadow systems
В виду большого количества кейсов, где сотрудники используют Excel, следует отдельно рассмотреть термин shadow system и связанные с ним вопросы
Shadow system — термин, используемый в IT для любого приложения, на которое полагаются бизнес-процессы, которые не находятся под юрисдикцией централизованного отдела IT. То есть отдел информационных систем не создавал его, не знал о нем и не поддерживает его.
Теневые системы состоят из небольших баз данных и/или электронных таблиц, разработанных и используемых конечными пользователями, вне прямого контроля ИТ-отдела организации.
Процесс проектирования и разработки этих систем, как правило, попадает в одну из двух категорий. В первом случае эти системы разрабатываются на основе adhoc, а не как часть формального проекта, и не тестируются, не документируются и не защищаются с той же строгостью, что и более формально спроектированные решения для отчетности. Это делает их сравнительно быстрыми и дешевыми в разработке, но в большинстве случаев непригодными для долгосрочного использования. Во втором случае системы разрабатываются опытными разработчиками программного обеспечения, которые не являются частью отдела информационных систем организации. Эти системы могут быть готовыми программными продуктами или индивидуальными решениями, разработанными программистами. В зависимости от опыта разработчиков эти решения могут превосходить по надежности решения, созданные отделом информационных систем организации.
Многие компании полагаются на электронные таблицы как на ключевой компонент в своей финансовой отчетности и операционных процессах. Однако очевидно, что гибкость электронных таблиц иногда обходится дорого. Важно, чтобы руководство определило, где сбои в контроле могут привести к потенциальным существенным искажениям, и чтобы контроль для значительных электронных таблиц был задокументирован, оценен и протестирован. И, возможно, что еще важнее, руководство должно оценить, возможно ли внедрить адекватный контроль для значительных электронных таблиц, чтобы в достаточной степени снизить этот риск, или следует ли перенести электронные таблицы, связанные со значительными счетами или с более высокой сложностью, в прикладную систему с более формализованной средой контроля информационных технологий.
Теневые системы подвержены следующим проблемам:
Плохо спроектированы Теневые системы часто страдают от плохого дизайна. Ошибки может быть трудно найти, модификации могут быть сложными, а долгосрочная поддержка может быть проблематичной.
Не масштабируемы Обычно теневые системы используются только одним или двумя людьми. Если они не разработаны опытными программистами, может быть сложно масштабировать их для поддержки десятков или сотен пользователей.
Плохо документированы Теневые системы часто не имеют адекватной документации. Знания о системе передаются из уст в уста и могут быть ограничены очень небольшим количеством людей. Эти знания затем полностью теряются, если один или два сотрудника уходят.
Непроверенные Около двух третей усилий, затрачиваемых на профессиональную разработку программного обеспечения, тратятся на тестирование. Теневые системы проходят гораздо более поверхностное тестирование и могут иметь скрытые ошибки, которые становятся очевидными только после длительного периода использования в производстве.
Несанкционированный доступ к конфиденциальной информации Теневые системы хранят значительные объемы данных компании и могут включать конфиденциальную информацию о клиентах, поставщиках или персонале. Процессы контроля доступа для этих систем часто гораздо более нестрогие, чем для централизованной базы данных компании, и могут вообще не существовать. Физическое размещение конфиденциальных данных на настольных компьютерах или ноутбуках может сделать организацию очень уязвимой в случае кражи компьютера.
Легко допустить ошибки Данные в электронных таблицах можно очень легко изменить, как намеренно, так и нет. После изменения может быть сложно отследить, какие изменения были внесены и как выглядели исходные данные.
Резервное копирование Теневые системы часто не регулярно резервируются.
Несколько версий правды В организации может быть много разных теневых систем, отчитывающихся по одним и тем же данным. Каждая из них может добавлять фильтры и манипулировать данными по-разному. Это может привести к очевидным несоответствиям в их выводе.
Карта автоматизации
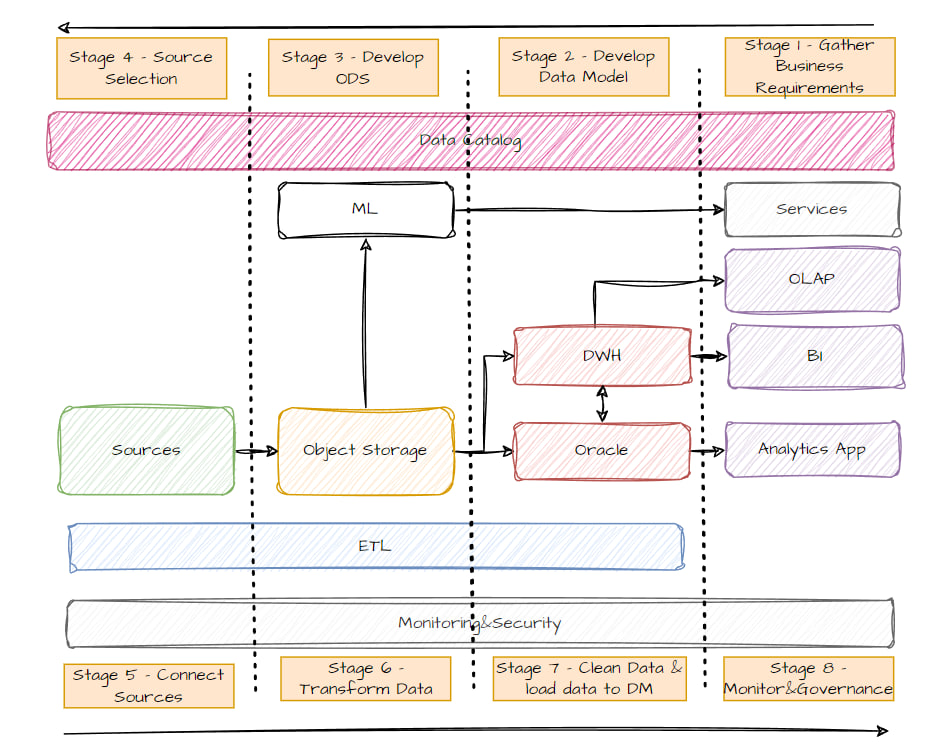
Жизненный цикл
Успешный рефакторинг возможен при строго определенном жизненном цикле, который отвечает не только на стратегические вопросы: что мы делаем и в какой последовательности, но и на тактические: как именно мы делаем. Такая организация процесса позволяет не отклониться от курса и добиться выполнения поставленных целей.
Схематично жизненный цикл можно отобразить следующим образом:

Program Management
Отвечает за конечный результат и может быть представлено в виде крупных блоков задач. Каждая из которых затем проходит более детализированное планирование в блоке Program Planning, где после сбора и анализа требований каждый блок задач разбивается на три трека:
- Архитектурный (проектирование и выбор продуктов)
- Имплементации (производство добавочной стоимости)
- Бизнес-польза (использование результатов конечными потребителями)
В данном проекте можно выделить следующие блоки задач в качестве программ в порядке реализации:
| Программа | Значимость | Артефакты |
|---|---|---|
| Выбор пути развития (on-prem, cloud, hybrid, open source, paid) | Решения в данном в блоке будут оказывать долгосрочное влияние на развитие проекта. Решения должны быть проанализированы и зафиксированы в качестве стратегии развития на самом раннем этапе | Стратегия развития, фундаментальные требования к выборам продуктов, требования к сотрудниками по компетенциям и опыту |
| Каталогизация данных QlickView | Глубокое погружение в архитектуру данных внутри QlickView позволит лучше сформировать требования к конечному результату. Кроме того движение от конечного пользователя принесет более быстрые результаты в бизнесе и позволит лучше сфокусироваться на конкретных потребностях, в отличие от методологии, которая начинает анализ с источников данных, что может привести к слишком детальному и глубокому погружению в процессу без видимого бизнес эффекта. | Каталог данных, подключенный к QlickView, список витрин данных, описание их структуры, список потребляющих данных пользователей, привязка витрин данных к бизнес-процессам, бизнес-глоссарий, процесс получения доступа, процесс рефакторинга, процесс создания новых витрин данных и дашбордов, требования к новому продукту для визуализации данных |
| Элиминация теневых систем (excel) | Уход от множества эксель файлов позволит увеличить производительность труда, повысит качество данных, обеспечит высокую удовлетворенность сотрудников | Список эксель файлов, которые используют данные из хранилища данных или поставляют данные в хранилище данных с привязкой к бизнес-процессу и группе пользователей, новая архитектура, регламентированный процесс по переходу на новую архитектуру, план перехода на новую архитектуру |
| Каталогизация данных хранилища данных | Постановка текущих данных на учет позволит проводить анализ по функциональным разрывам между требованиями от визуализации данных и фактическим положением вещей | Гэп между требованиями визуализации данных и поставляемыми данными из хранилища данных, архитектурное решение по выбору методологии моделирования данных, требования для выбора продукта по хранению данных, настроенный процесс по созданию элементов модели данных, методология работы с качеством данных |
| Учет ETL процессов | Постановка ETL процессов на учет позволит провести анализ и выбрать подходящий продукт для миграции | Требования по загрузке данных, мониторинг ETL процессов, обеспечение технического качества данных, внедрение распределенного файлового хранилища данных, сбор метаданных источника |
| Продвинутая аналитика | Новая практика для компании | Модели машинного обучения |
Таким образом выбор каждой программы основан на движении от пользовательских потребностей и быстрых бизнес результатов к технологической части. Каждая программа характеризуется метриками успешности, где выбираются объекты для учета, а затем уже технологические инструменты для этого учета и для организации процессов по работе с объектами учета. Это дает возможность с самого начала строить прозрачные масштабируемые решения, которые не будут зависеть от внешних обстоятельств или от конкретных ролей на проекте.
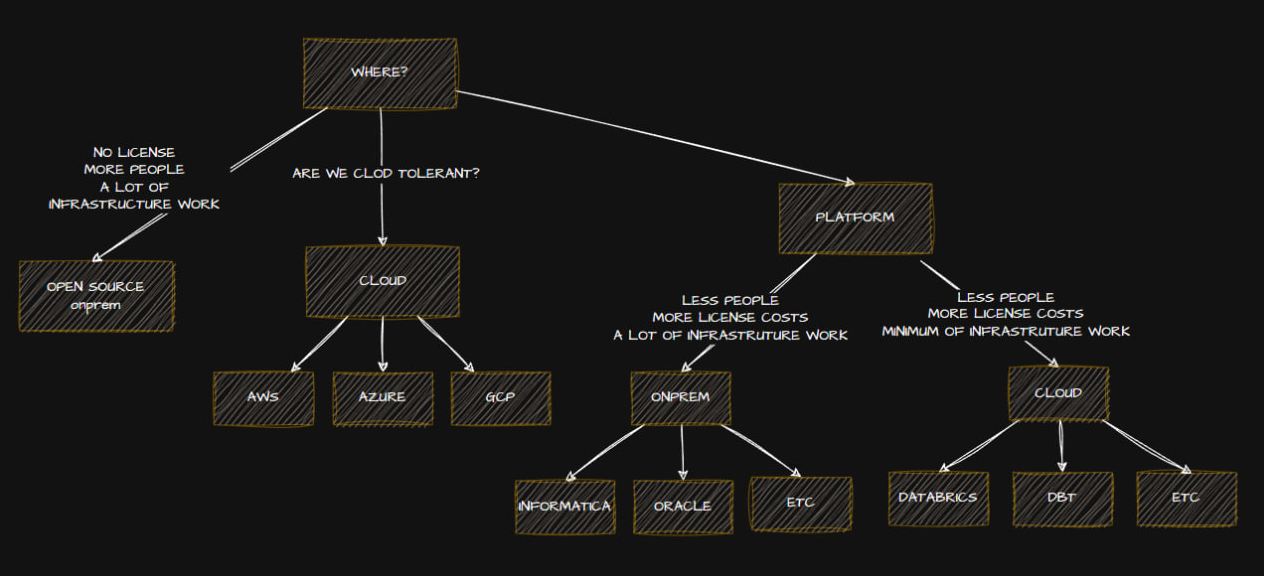
Выбор пути развития
Следует рассмотреть, дополнить и заполнить следующий шаблон
| Criteria/Option | On prem Open Source | On prem Paid | On prem semi paid | Cloud | Hybrid |
|---|---|---|---|---|---|
| Maintenance | |||||
| Costs | |||||
| Flexibility | |||||
| Competences & skills | |||||
| Security | |||||
| Legal aspects | |||||
| Latency | |||||
| Time-to-market | |||||
| Traffic costs | |||||
| DevOps | |||||
 |
Каталогизация данных QlickView
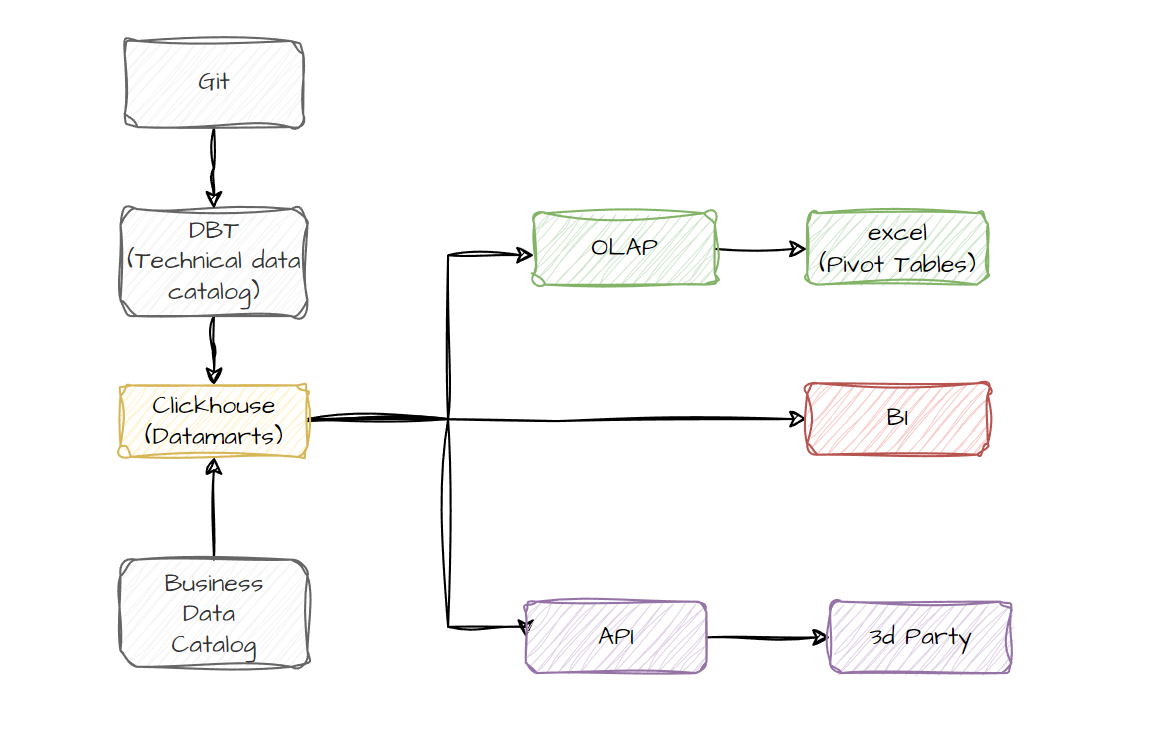
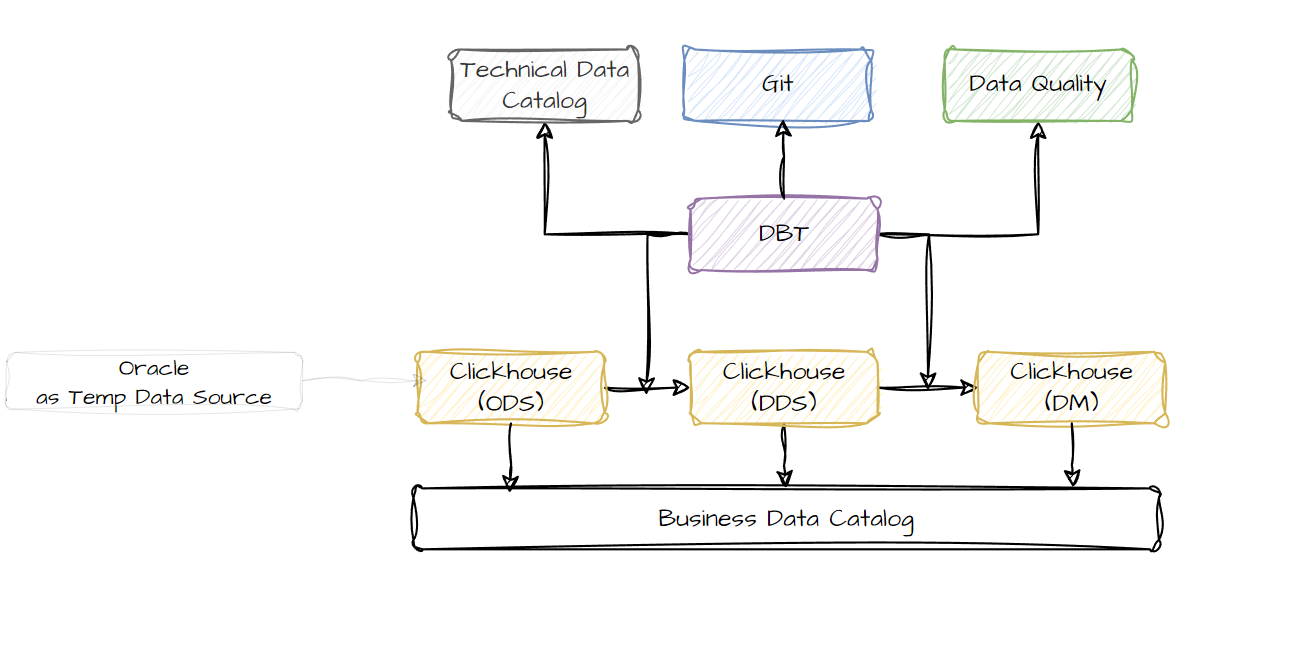
Данная архитектура обладает следующими свойствами:
- Основным поставщиком данных является слой витрин данных на базе Clickhouse. Clickhouse изначально создавался для обработки больших массивов информации с высокой скоростью отдачи конечных результатов для потребления
- Описание бизнес данных, бизнес-глоссарий и его связь с данными, а также процесс запроса получения доступа к данным осуществляются с помощью каталога данных
- Технический каталог данных с необходимой технической информации, линеджем данных и метриками качества данных осуществляются с помощью инструмента DBT
- За контроль версии, процессы CI/CD и командную работу отвечает система контроля версии, обозначенная на схеме как Git
Доступ к данным возможен тремя способами:
- Классическая BI система. Clickhouse поддерживает все широко распространенные системы BI аналитики. Выбор конкретной системы должен быть осуществлен в ходе детального рассмотрения требовании при исполнении программы
- Наиболее популярный и востребованный метод работы с данными для middle - management’а это механизм сводных таблиц, который позволяет на лету исследовать данные и получать необходимые разрезы. Пилотный проект показал, что воспроизвести OLAP механику работы с данными возможно. Сценарий можно посмотреть по ссылке (2 мин)
- Clickhouse имеет встроенное API для получения данных. В случае наличия отдельных требований по безопасности данный функционал может быть обернут в самописный компонент. Аналогично может быть рассмотрено решение с рынка или использован Oracle Apex, который будет детально описан ниже.
Так же после более детального рассмотрения требований способы доступа к данным могут быть расширены.
Элиминация теневых систем
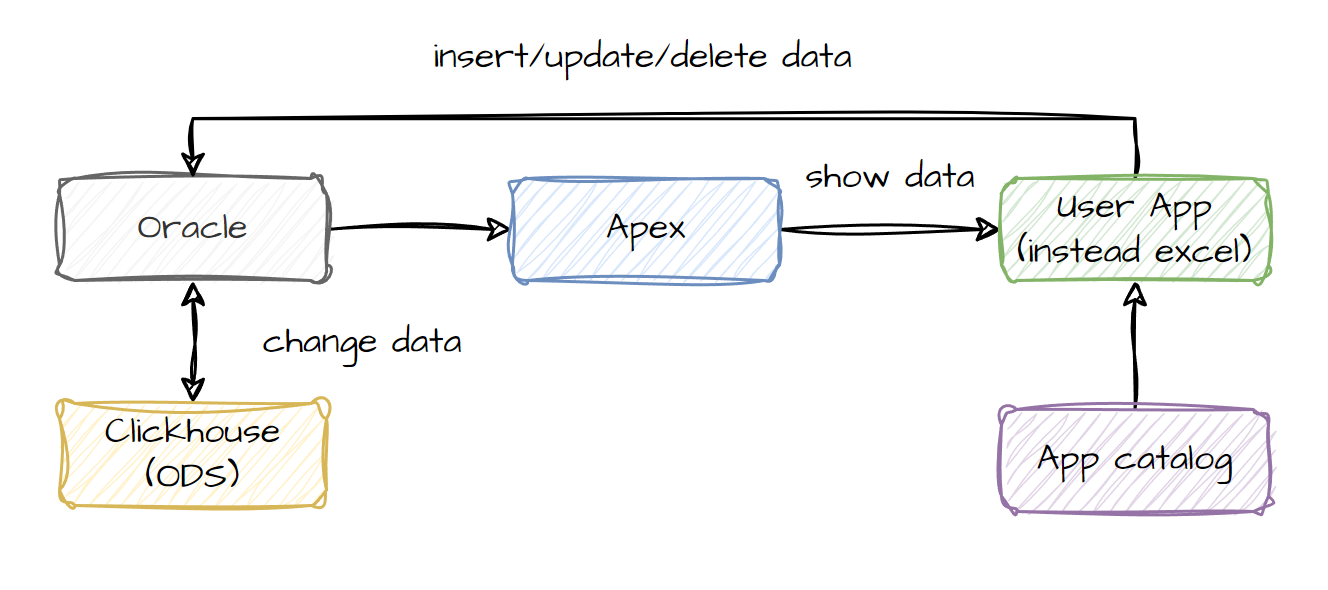
Компания в настоящий момент использует Oracle, что дает возможность без приобретения дополнительных лицензий использовать технологию Oracle Apex
Данная технология позволяет быстро разрабатывать пользовательские приложения в том числе аналитические приложения с возможностью изменения данных.
Oracle Apex обладает следующими возможностями:
Быстрая разработка приложений
Компания имеет большое количество незавершенных приложений в стадии разработки, которые необходимы ей для часто меняющихся бизнес потребностей и сохранения конкурентоспособности на рынке. Как правило, эти решения не относятся к классу enterprise систем, они могут требоваться на короткий промежуток времени, но нужны “вчера”. Требования могут быть плохо определены, а приоритеты быстро меняться, поэтому приложения должны создаваться очень быстро и легко обновляться по мере необходимости.
Замена Excel
Электронные таблицы очень легко создавать, любой может составить электронную таблицу, если у него есть данные. После создания эти файлы часто отправляются коллегам для обновления и других операций. Это неизбежно приводит к многочисленным копиям с разными данными и очень несовершенной работе бизнес-процессов. Гораздо лучшее решение - иметь единый источник достоверной информации, хранящийся в полностью защищенной базе данных с приложением на основе браузера, которое каждый может использовать для работы с данными.
Мобильные рабочие места
Быстрое создание мобильных рабочих мест или замена устаревших интерфейсов
Внешний обмен данными
Часто бывает необходимо обмениваться данными с партнерами, но на практике это превращается в сложный и запутанный бизнес процесс. Предоставление партнерам приложения, позволяющего взаимодействовать с компанией может значительно повысить эффективность взаимодействия. Однако, информационная безопасность не хочет выставлять внутренние системы в интернет. Применение технологии позволит выстраивать полностью защищенную и приватную инфраструктуру вокруг приложения.
Внешний обмен данными
Получение полной и точной картины в масштабах компании или даже внутри отдела часто бывает очень сложной задачей. Данные хранятся во многих системах, существующие отчеты ограничены и не всегда содержат необходимую информацию для принятия обоснованных бизнес-решений, трудно ограничить, кто что может видеть, и избежать утечки данных, а расчет готовых отчетов может занимать несколько часов. Технология позволит организовать индивидуальные аналитические приложения.
Интеграция с ERP, CRM
ERP системы предоставляют широкий набор функционала, однако они не всегда могут предоставить конкретный отчет под специфические нужды или могут отсутствовать функции необходимые для отрасли или компании. В этих случаях создание расширение этих систем с помощью небольшого бизнес-приложения может помочь предоставить соответствующую информацию или значительно повысить эффективность бизнес-процесса и производительность труда, а так же удовлетворенность конечных пользователей.
Представленная архитектура реализуется следующим образом:
- Существующий в компании Oracle постепенно выводится из роли хранилища данных для аналитики
- Производится даунгрейд по лицензиям и ресурсам, чтобы снизить стоимость владения Oracle
- Настраивается входящий в существующую лицензию компонент Oracle Apex, который позволяет начать создавать аналитические приложения и заменять Excel
- Данные в приложениях делятся на две части: поставляемые из хранилища данных (без возможности изменения) и генерируемые пользователем внутри приложения
- Данные генерируемые пользователем могут поставляться на слой ODS основного хранилища данных и в дальнейшем использоваться в стандартных витринах данных
- Данные из хранилища могут поставляться в пользовательские приложения через интеграцию Oracle и Clickhouse
- Для процессов управления созданием приложений, получений доступа к существующим приложениям, документирования приложений внедряется компонент Каталог приложений
Каталогизация данных хранилища данных
Основным компонентом для хранения и обработки данных в данном варианте архитектуры является Clickhouse, который организован из слоев:
- ODS - Operational Data Store
- DDS - Detail Data Store
- DM - Datamarts (Слой витрин данных)
Слой витрин данных представляет собой плоские таблицы, сконфигурированные под конкретные аналитические задачи. Данный слой является финишным и предназначен для конечного потребителя.
Слой детальных данных
Слой витрин данных решает специфические группы задач, но при этом большинство витрин данных используют повторяющиеся сущности: клиент, заказ, транзакция, товар и т.д. Но делают это с разным набором атрибутов, в разных разрезах, с разными фильтрами и т.д. Чтобы не воспроизводить каждый раз повторяющийся набор действий при производстве витрины данных: выделение сущности, выделение бизнес-ключа сущности, моделирование ее атрибутов, работа с качеством данных и т.д. выделяется отдельный слой, который содержит все общие сущности и процессы на детальном уровне.
Кроме того, этот слой выступает единым источником правды, так как в отдельных витринах за счет разных уровней агрегации, фильтрации и т.д. - данные могут расходиться.
Третье назначение этого слоя - абстрагирование от конкретных учетных систем. Независимо от того, в какой системе ведется учет клиентов или транзакции, сама сущность клиент не зависит от поставщика данных. Клиент и транзакция существуют пока существует бизнес, а вот IT системы может не быть (учет в бумажных журналах). Таким образом слой DDS защищает конечное потребление данных от конкретных учетных систем и позволяет легче осуществлять переход с одной учетной системы на другую.
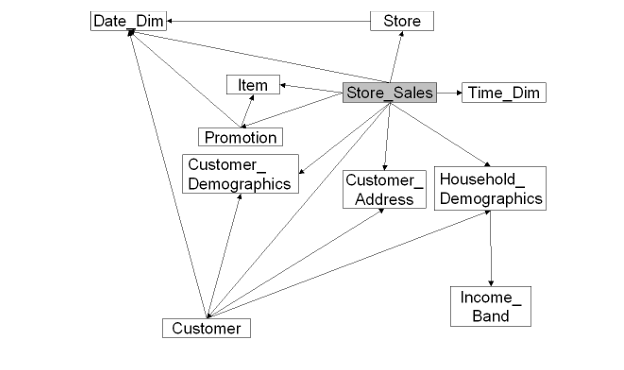
В розничной торговле выделяют следующие области DDS:
| Subject Area | Description |
|---|---|
| Customer | Информация о розничных клиентах, корпоративных клиентов |
| External | Данные из внешних систем, например от Nielsen |
| CRM | Данные о коммуникациях с клиентами, проведенными кампаниями, контакты клиента, данные опросов |
| Item | Данные о SKU, цены, история изменения цен, промоакции, иерархия |
| Location | Информация о точках продаж, как физических так и виртуальных |
| Order | Данные о заказах (через телефон, интернет, каталог) |
| Organization | Данные об организации, организация может быть как внутренней так и внешней |
| Supply Chain | Информация о цепочках поставок |
| Retail Transaction | Информация о чеках |
Данные области с точки зрения логической модели данных могут быть представлены следующим образом:
Продажи через оффлайн канал (магазины)
Слой операционных данных
Детальный слой содержит абстрагированные от конкретных систем данные, при этом данные для одной сущности могут приходить из разных систем. Соответственно необходимо сохранить данные из разных систем, чтобы сопоставить их и принять решение: чья версия правды будет поставлена в DDS/
Кроме того, данные из системы по какой-либо сущности не приходят в виде единой таблицы, , в большинстве случаев это группа таблиц в которых содержатся различные атрибуты одной сущности. Необходимо убедиться в ссылочной целостности этих данных, после чего объединить и поставить в DDS.
Таким образом, чтобы иметь возможность получить данные, приближенные к исходной системе, как по содержанию так и по структуре необходим слой ODS. Он позволяет очистить данные от технической информации, сохранив линедж на исходную систему и проводить анализ и преобразование данных без нагрузки на исходную систему.
Еще одна цель существования этого слоя - необходимость поставить сырую необработанную информацию моделям машинного обучения, которым зачастую не хватает рафинированного бизнес контекста из слоя DDS.