dbt — это стандарт для создания надёжных и управляемых наборов данных на основе структурированной информации. MCP (Model Context Protocol) становится важным способом передачи контекста большим языковым моделям (LLM), чтобы они могли эффективно работать в реальных задачах.
Ожидается, что в будущем структурированные данные будут активно использоваться в AI-процессах, а dbt будет играть ключевую роль в их подготовке.
Бизнес-аналитика и инженерия данных всё больше будут опираться на ИИ, который работает на основе контекста из проектов dbt.
Команды данных сосредоточатся на том, чтобы формировать богатый контекст для MCP. Благодаря этому ИИ и бизнес-пользователи смогут работать в системах, где LLM используют данные из dbt-проектов как основу для принятия решений.
Что такое MCP?
MCP расшифровывается как Model Context Protocol — это открытый протокол, представленный компанией Anthropic в ноябре прошлого года. Он предназначен для того, чтобы позволить AI-системам динамически получать контекст и данные.
Почему это важно?
Даже самые продвинутые модели остаются ограниченными, если не имеют доступа к данным — они “заперты” внутри информационных изоляторов и устаревших систем. Каждый новый источник данных требует индивидуальной интеграции, из-за чего создание по-настоящему связанных систем сложно масштабировать.
MCP решает эту проблему. Это универсальный и открытый стандарт, который позволяет подключать AI-системы к источникам данных, заменяя разрозненные интеграции единым протоколом.
– Anthropic
С момента релиза MCP получил широкую поддержку: Google, Microsoft и OpenAI подтвердили намерение поддерживать этот протокол.
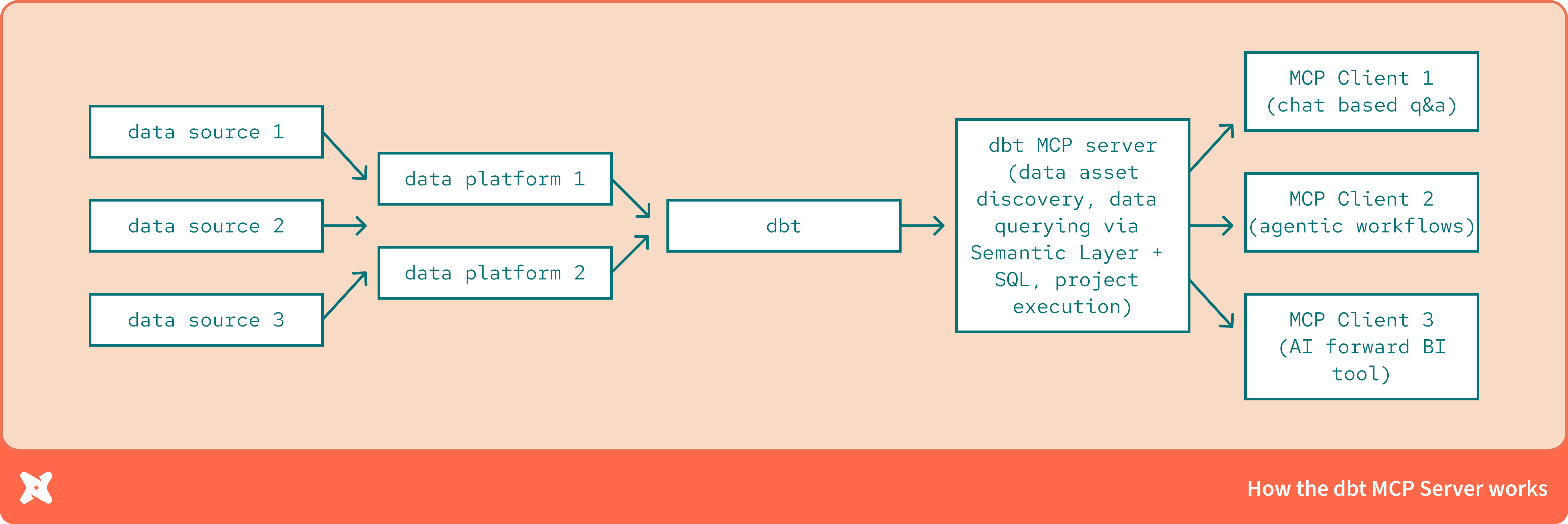
Что делает сервер dbt MCP?
Представьте его как недостающее звено между:
-
вашим проектом dbt (модели, документация, lineage, семантический слой)
-
и любым клиентом, поддерживающим MCP (например, Claude Desktop Projects, Cursor, фреймворки для агентов, собственные приложения и т.д.)
Уже давно понятно, что сочетание структурированных данных из проекта dbt и больших языковых моделей (особенно при использовании семантического слоя dbt) дает невероятный прирост операционной эффективности.
Сервер dbt MCP предоставляет набор инструментов, которые работают поверх проекта dbt. Эти инструменты могут вызываться LLM-системами для получения сведений о данных и метаданных.
Основные функции dbt MCP
-
Обнаружение данных (Data discovery)
Позволяет понять, какие данные и артефакты содержатся в проекте dbt. -
Запрос данных (Data querying)
Даёт возможность напрямую обращаться к данным в вашем dbt-проекте. Сюда входят два варианта:-
Использование семантического слоя dbt для получения достоверных метрик.
-
Выполнение SQL-запросов для анализа и разработки.
-
-
Выполнение команд в dbt
Обеспечивает доступ к интерфейсу командной строки dbt (CLI) для запуска проекта и выполнения других операций.
Использование сервера dbt MCP для обнаружения данных
dbt обладает знанием обо всех данных в стекe — от “сырых” staging-моделей до готовых аналитических витрин. Сервер dbt MCP делает это знание доступным для больших языковых моделей (LLM) и AI-агентов, раскрывая мощные возможности по обнаружению данных:
-
Для бизнес-пользователей:
Возможность изучать продуктивный dbt-проект в интерактивной форме, используя естественный язык.
Например, можно задать вопросы:
«Какие данные по клиентам у нас есть?» или «Где хранятся сведения о маркетинговых расходах?» — и получить точную информацию, основанную на документации и структуре проекта dbt. -
Для AI-агентов:
Автоматическое обнаружение и понимание доступных моделей данных, их связей и структуры — без участия человека.
Это позволяет агентам самостоятельно ориентироваться в сложной среде данных и генерировать точные аналитические выводы.
Такой контекст особенно важен для агентов, которым нужно работать с информацией в рамках дата-платформ.
Инструменты обнаружения данных помогают LLM понять:
-
какие данные существуют,
-
как они организованы,
-
как связаны между собой разные модели.
Это контекстное понимание критично для:
-
генерации корректных SQL-запросов,
-
ответов на бизнес-вопросы,
-
предоставления достоверных аналитических данных.
Инструменты для обнаружения данных (Data Asset Discovery Tools)
⚠️ Важно: все эти инструменты вызываются автоматически. Не требуется использовать их напрямую в своей работе — MCP-клиент сам определяет, какой из инструментов наиболее уместен в конкретной ситуации на основе предоставленного контекста.
| Название инструмента | Назначение | Результат |
|---|---|---|
get_all_models | Предоставляет полный перечень всех моделей в dbt-проекте, вне зависимости от их типа | Список всех моделей с их названиями и описаниями |
get_mart_models | Определяет модели уровня представления, предназначенные для конечных пользователей | Список моделей витрин (reporting layer) с названиями и описаниями |
get_model_details | Предоставляет подробную информацию о конкретной модели | Скомпилированный SQL, описание модели, названия колонок, описания колонок и их типы данных |
get_model_parents | Определяет, от каких моделей зависит заданная модель (восходящие зависимости) | Список родительских моделей, от которых зависит указанная модель |
Семантический слой dbt
Семантический слой dbt задаёт метрики и измерения в согласованной и управляемой форме. С помощью сервера dbt MCP большие языковые модели (LLM) могут понимать и запрашивать эти метрики напрямую, что обеспечивает соответствие AI-анализов корпоративным определениям и стандартам.
-
Для бизнес-пользователей:
Можно запрашивать метрики с помощью естественного языка.
Например: «ежемесячная выручка по регионам» — и получить точные результаты, соответствующие стандартным определениям метрик в организации.
Это обеспечивает более высокую точность, чем при генерации SQL напрямую через LLM. -
Для AI-агентов:
По мере того как агентные системы начинают действовать в реальном мире на длительном горизонте, им нужно уметь понимать бизнес-контекст.
Будь то генерация исследовательских отчётов или работа операционных агентов — Семантический слой dbt может выступать в роли надёжного интерфейса между ИИ и бизнес-реальностью.
Использование семантического слоя через MCP-сервер позволяет LLM опираться на чёткие и формализованные определения метрик, заданные в виде кода, и применять их в любом клиенте с поддержкой MCP.
Инструменты семантического слоя (Semantic Layer Tools)
| Название инструмента | Назначение | Результат |
|---|---|---|
list_metrics | Предоставляет перечень всех доступных метрик в семантическом слое dbt | Полный список метрик: названия, типы, ярлыки и описания |
get_dimensions | Показывает, какие измерения доступны для указанных метрик | Список измерений, которые можно использовать для группировки или фильтрации метрик |
query_metrics | Выполняет запросы к метрикам из семантического слоя | Результаты запросов на основе указанных метрик, измерений и фильтров |
Использование сервера dbt MCP для выполнения SQL-запросов (Text-to-SQL)
Семантический слой dbt обеспечивает управляемый подход к работе с данными на основе метрик, но во многих случаях требуется более гибкая аналитика с использованием произвольных SQL-запросов.
-
Для бизнес-пользователей:
Возможность задавать сложные аналитические вопросы, выходящие за рамки заранее определённых метрик.
Пользователи могут свободно исследовать данные, пользуясь пониманием моделей данных со стороны LLM, что повышает точность и оптимизацию сгенерированных SQL-запросов. -
Для AI-агентов:
Автоматическая генерация и валидация SQL-запросов на основе моделей данных.
Агенты могут строить и выполнять сложные запросы, адаптирующиеся к изменениям схем, оптимизирующие производительность и соответствующие корпоративным стандартам написания SQL.
В отличие от традиционного генератора SQL, сервер dbt MCP создаёт запросы с учётом конкретных моделей данных организации, что делает их точнее и полезнее в конкретном окружении.
Эта функциональность особенно полезна для:
-
гибкой аналитики;
-
разовых исследований;
-
прототипов, которые в будущем могут быть включены в основной проект dbt.
На данный момент выполнение SQL реализовано через инструмент dbt show,
но в ближайшее время планируется выпуск более производительных инструментов, специально заточенных под задачи text-to-sql.
Использование сервера dbt MCP для запуска и управления проектом
Сервер dbt MCP предоставляет не только доступ к данным — он также позволяет большим языковым моделям (LLM) и AI-агентам напрямую взаимодействовать с dbt, выполнять команды и управлять проектом.
-
Для бизнес-пользователей:
Возможность запускать команды dbt через разговорные интерфейсы без знания командной строки.
Например, пользователь может сказать: «запусти ежедневные модели» или «протестируй модели клиентов» — и получить понятные результаты с пояснениями и рекомендациями по устранению возможных проблем. -
Для AI-агентов:
Автономное выполнение процессов dbt в ответ на события.
Агенты могут:-
запускать и управлять выполнением проекта;
-
автоматически тестировать и проверять изменения в моделях;
-
самостоятельно диагностировать и устранять типовые ошибки — без участия человека.
-
Если инструменты обнаружения и запросов работают “поверх” окружения (используя его как источник контекста),
то инструменты выполнения напрямую взаимодействуют с CLI, включая как dbt Core, так и dbt Cloud CLI.
Инструменты управления выполнением проекта (Project Execution Tools)
| Название инструмента | Назначение | Результат |
|---|---|---|
build | Выполняет команду dbt build для сборки всего проекта | Результаты сборки: статус выполнения (успех/ошибка), логи |
compile | Выполняет команду dbt compile для компиляции SQL-кода проекта | Результаты компиляции: статус (успех/ошибка), логи |
list | Выводит список всех ресурсов в проекте dbt | Структурированный список всех ресурсов проекта |
parse | Выполняет синтаксический разбор файлов проекта dbt | Результаты парсинга: статус (успех/ошибка), логи |
run | Выполняет команду dbt run для запуска моделей в проекте | Результаты выполнения: статус (успех/ошибка), логи |
test | Выполняет тесты, определённые в проекте dbt | Результаты тестов: статус выполнения (успех/ошибка), логи |