Смотрим в корень
В мире хранения и обработки больших данных система управления базами данных Greenplum очень известна. Созданная на основе PostgreSQL она добавила возможность использовать хорошо известный движок postgres в OLAP сценариях.
Такой трюк удалось провернуть благодаря массово-параллельной архитектуре (MPP). В результате пользователь взаимодействует с мастер нодой, которая отвечает за входящие соединения к кластеру и распараллеливает sql-запросы по отдельным нодам. Таким образом если таблица А равномерна распределена по кластеру и на каждой ноде лежит часть таблицы, то запрос вида:
select count(id) from A;под капотом превратиться в серию параллельных запросов:
select count(id) from A_Part1;
select count(id) from A_Part2;
select count(id) from A_Part3;Каждая нода выполнит свою часть работы, после чего мастер ноде потребуется объединить результаты работы в конечный ответ пользователю.
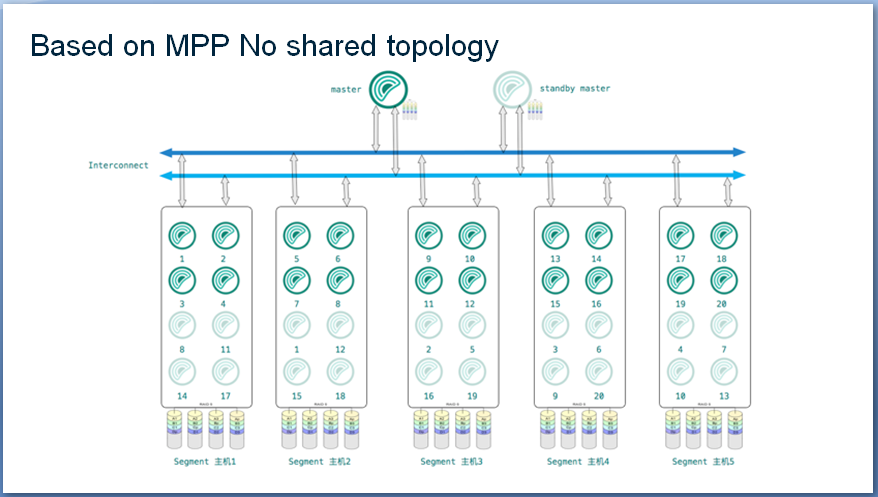
Исходя из такого незатейливого объяснения, можно выделить для себя ряд важных нюансов:
- существует точка отказа в виде мастер ноды, которая частично решается репликой мастер ноды
- GP чувствителен к архитектуре данных (стратегии их распределения и партицирования)
- масштабирование кластера не является очевидной процедурой и скорее всего приведет к перекосу распределения таблиц в кластере с соответствующим влиянием на производительность кластера
- GP очень чувствителен к сети. Для взаимодействия с сетью GP использует технологию Interconnect, которая работает на более быстром протоколе UDP по сравнению с TCP GP может вести себя не стандартно на классических виртуалках облачного провайдера, особенно если он по умолчанию не поставляет вам гигабитную сеть между ними. Так же перед вами может стоять вопрос: как раскидать кластер между разными региональными центрами?
- отдавать большое количество детальных данных, хранящихся в GP, в третью систему - плохая идея
- писать данные в много потоков через jdbc и мастер ноду - плохая идея
- большая частота пользовательских запросов может стать проблемой
- организация движения данных приближенных к реальному времени является не тривиальной задачей
Тренды open source
Современный мир движется к де-глобализации, а значительная часть open-source проектов движется к закрытию и переходу на коммерческие рельсы. В мире данных этот тренд особенно заметен.
Все более значительная часть open source проектов представляет из себя демо-версию технологии. Помните старые добрые trial версии продуктов? На мой взгляд, в течении 5 лет нас ждет цунами из trial версий продуктов. И если философия open source “посмотри и доделай сам”, то нас ждет возврат ко временам “посмотри и купи, сам доделать не сможешь”.
Яркий представитель подобного тренда DBT , который методично сокращает документацию открытой части проекта, заменяя ее на документацию коммерческой облачной версии технологии. Маркетинг захватил мир open source.
Greenplum не стал исключением. На текущий момент репозитории GP заархивированы на гитхабе. Но перед своей кончиной он успел породить множество коммерческих деривативов. Наиболее известный на российском рынке ADB (Arenadata DB)
В основном, производные продукты сосредоточили свое внимание на обвязке, которая требуется при промышленной эксплуатации: средства развертывания кластера, его расширения, мониторинг и т.д.
Изменение фундаментальных недостатков практически не затрагивалось и это было связано с многочисленными ограничениями, которые накладывает ядро технологии - postgresql. Однако, это не остановило инженерную мысль. И к своему удивлению, я обнаружил, что на конкурентом рынке свидетелей greenplum’а в 2024 году появился еще один продукт от китайских коллег - YMatrix.
Особенности YMatrix
Из интересных возможностей продукта можно выделить следующие:
- движок для стриминга данных (Domino)
- векторизированное исполнение запросов
- само адаптирующаяся компрессия данных (pattern-based-chain-style encoding)
- хранение данных в формате MARS3
- решение по загрузке данных в кластер без использования мастер ноды (Master Gate)
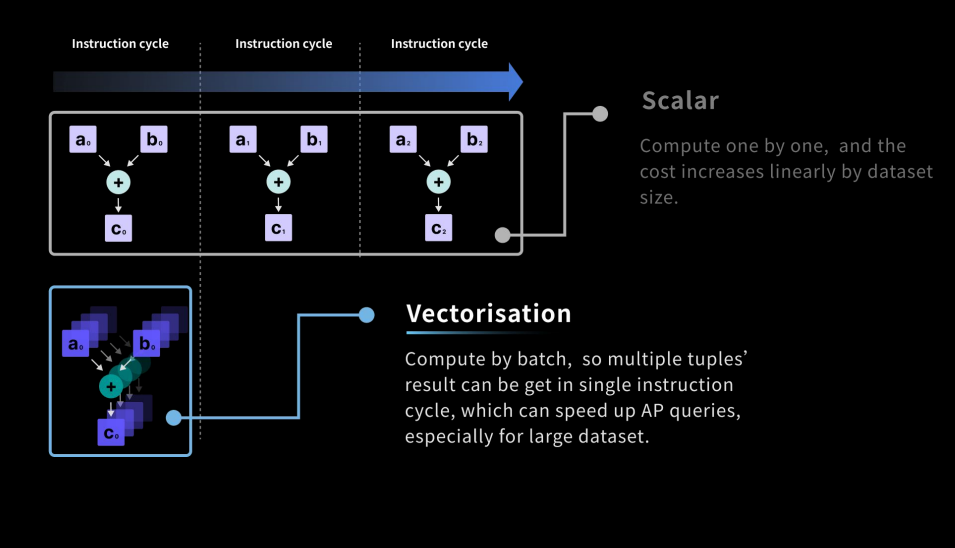
Векторизированное исполнение запросов
Векторизованное выполнение было популяризировано командой MonetDB/X100. Эта идея основана на наблюдении, что большинство движков баз данных следуют модели выполнения на основе итераторов, где каждый оператор базы данных реализует метод next().
Каждый вызов next() создает один новый кортеж, который, в свою очередь, может быть передан другим операторам. Эта модель «кортеж за раз» вносит накладные расходы на интерпретацию и также отрицательно влияет на высокопроизводительные функции современных ЦП.
Векторизованное выполнение снижает эти накладные расходы за счет использования массовой обработки. В этой новой модели, вместо того чтобы создавать один кортеж при каждом вызове, next() работает и создает пакет кортежей (обычно 10-100 КБ).
Clickhouse активно использует эту технологию.
Движок для стриминга данных (Domino)
Помните KSQL? Движок SQL для Apache Kafka и как с его помощью было легко работать со потоковыми данными?
Можно было легко создать захватчик событий
CREATE SOURCE CONNECTOR riders WITH (
'connector.class' = 'JdbcSourceConnector',
'connection.url' = 'jdbc:postgresql://...',
'topic.prefix' = 'rider',
'table.whitelist' = 'geoEvents, profiles',
'key' = 'profile_id', ...);Запустить бесконечную потоковую трансформацию
CREATE STREAM locations AS
SELECT
rideId,
latitude,
longitude,
GEO_DISTANCE(latitude,
longitude,
dstLatitude,
dstLongitude
) AS
kmToDst
FROM geoEvents EMIT CHANGES;Создать материализованное представление
CREATE TABLE activePromotions AS
SELECT
rideId,
qualifyPromotion(kmToDst) AS promotion
FROM locations
GROUP BY rideId EMIT CHANGES;И использовать его для lookup
SELECT
rideId,
promotion
FROM activePromotions
WHERE ROWKEY = '6fd0fcdb';YMatrix позволяет организовать подобные кейсы с помощью привычного sql синтаксиса
MARS3
Интересный формат хранения данных/движок, который по своему описанию очень похож на движок AggregatingMergeTree , используемый в Clickhouse.
Мне не удалось найти никакой информации об этой технологии. Попалось только два патента для дальнейшего изучения:
- Patent No. US9081834 B2: Process for gathering and special data structure for storing performance metric data
- Patent No. US9081829 B2: System for organizing and fast searching of massive amounts of data
Вывод
YMatrix, на мой субъективный взгляд, это попытка найти баланс между Greenplum, Clickhouse и Kafka. И по первому впечатлению это удалось сделать хорошо.