Поиск — это диалог между пользователем и поисковой системой. Пользователь пытается удовлетворить свои информационные потребности, задавая поиску соответствующие фильтры, описывающие релевантный контент. Поисковая система использует эти ограничения, чтобы собрать подходящие результаты и представить их пользователю. Если пользователь удовлетворён найденным результатом, он начнёт изучать отдельные элементы более подробно. В противном случае он уточнит критерии поиска и попробует снова.
Ваша задача — облегчить этот диалог. Вы должны обеспечить релевантность результатов поиска и помочь пользователю понять, почему именно эти результаты были найдены, тем самым позволяя ему точнее формулировать запросы.
Но создание релевантного поиска требует гораздо больше усилий, чем может показаться на первый взгляд. Новички в разработке поисковых систем воспринимают поиск как чёрный ящик, в который вы добавляете контент и позволяете пользователям опрашивать его.
Под капотом поисковая система оперирует довольно примитивным сопоставлением терминов с использованием простых эвристик для ранжирования результатов. Поисковик — это механика: он не понимает смысла слов, не улавливает намерения пользователя и не учитывает контекст приложения.
Наука релевантности (relevance engineering) — это искусство заставить механический поисковый движок достигать целей по релевантности.
Помимо научного подхода к проектированию релевантности, есть и искусство: понимание того, что представляет собой хороший описательный признак (feature). Сюда также входит умение правильно взвешивать и балансировать различные факторы, чтобы соответствовать ожиданиям пользователей и бизнесу в отношении релевантности.
Первоначальное понимание поисковой системы может быть довольно простым: контент каким-то образом попадает в поисковую систему, а пользователи взаимодействуют с приложением поиска, отправляя запросы и исследуя результаты.
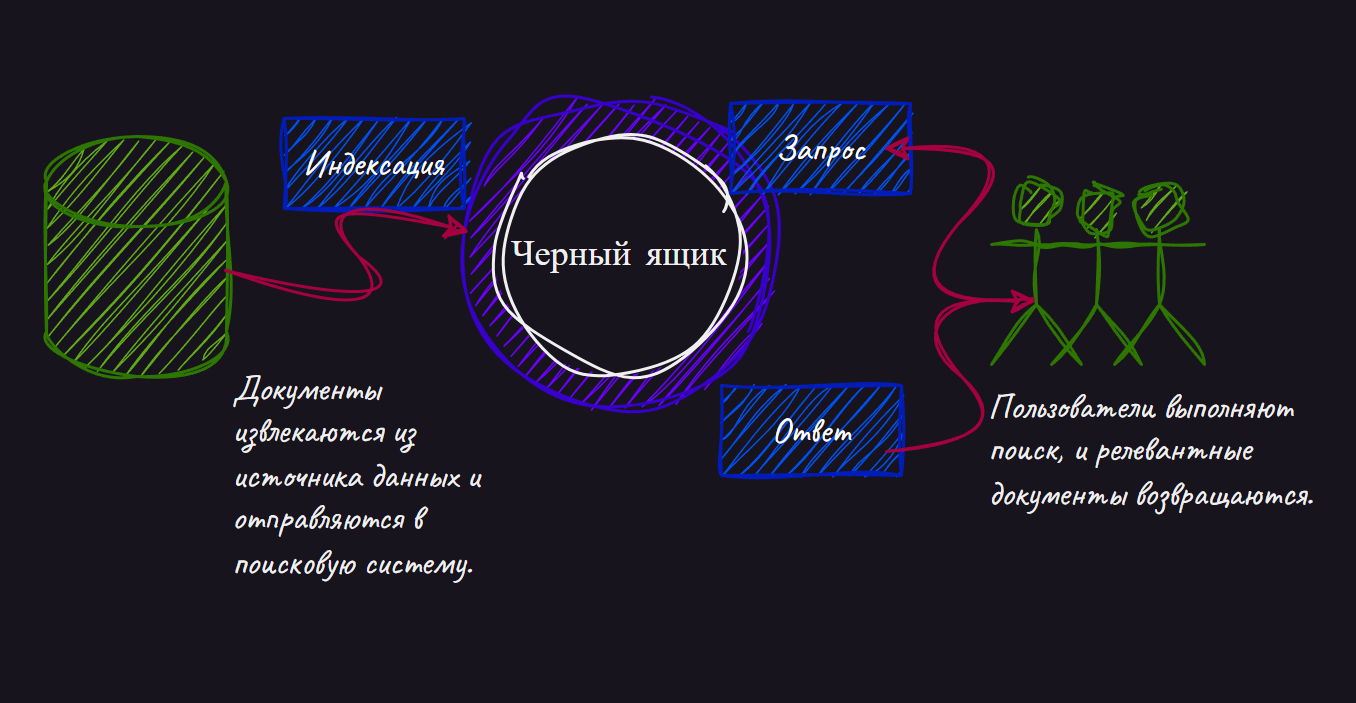
Прежде чем заглядывать под капот этого таинственного «чёрного ящика», давайте быстро рассмотрим возможности поисковой системы с точки зрения внешнего наблюдателя.
Как вам известно, основные функции поисковой системы — это хранение, поиск и извлечение контента. Хотя все эти понятия кажутся базовыми, будет полезно их повторить, чтобы установить общие определения и восполнить возможные технические пробелы.
В поисковых приложениях понятие документа является центральным, поскольку именно документы хранятся, ищутся и возвращаются пользователю. Документы — это то, ради чего существует поиск!
Когда вы отправляете запрос в поисковую систему, вы ищете по коллекции документов. Эти документы могут быть буквальными, например текстовыми файлами на сервере. Или, более широко, документы могут представлять контент, такой как:
-
товары в каталоге
-
песни, хранящиеся в MP3-плеере
-
люди в списке контактов
-
внутренние Word-документы на корпоративном портале
-
страницы книги
-
целые книги в библиотечной коллекции
Документ содержит набор полей — именованных атрибутов документа. В этом смысле документ похож на строку в таблице СУБД. Если в таблице СУБД содержится набор именованных столбцов и соответствующих им значений, то документ содержит набор полей с их значениями. Поля имеют типы, включая стандартные: строка (string), целое число (integer), число с плавающей запятой (float) и логический тип (Boolean).
Особый интерес для поиска представляют строки (string). Часто именно строки используются для поиска по содержимому. Например, в статье газеты под заголовком «Бизнес процветает на пляжах Анапы» вы, вероятно, захотите, чтобы запрос «пляжи Анапы» соответствовал тексту заголовка. Контроль над тем, при каких условиях текст соответствует запросу, займет значительную часть вашего времени как инженера по релевантности.
В отличие от таблиц СУБД, каждый документ может содержать различные поля. Поля в одном документе могут отличаться от полей в другом. Допустим, вы разрабатываете поиск по товарам, продающимся в сети магазинов у дома. Такие магазины предлагают широкий ассортимент продуктов. Хотя у всех товаров есть некоторые общие поля (например, название и цена), большинству типов товаров также требуются уникальные поля.
Книги в магазине, например, потребуют поля «автор» и «количество_страниц», а продукты питания — поля «калории» и «ингредиенты».
Теперь, когда мы определили понятие документа, можно поговорить о главной задаче поисковой системы: поиске релевантного контента!
Представьте, что ваша подруга Юля рассказывает вам о замечательной статье про пляжи Анапы. Она помнит, что статья была в разделе «Путешествия» газеты Коммерсант прошлым летом.
Желая поделиться этой статьёй с вами, Юля заходит на страницу поиска на kommersant.ru и выполняет поиск статьи, которая соответствует следующим критериям:
-
Опубликована в июне, июле или августе (ограничение по диапазону дат)
-
Размещена в разделе «Путешествия» (точное совпадение в строковом поле)
-
Ключевые слова анапа и пляж встречаются в заголовке и тексте статьи (поиск по совпадению в двух текстовых полях)
После того как заданы эти ограничения, поисковая система возвращает подходящие документы. Но она делает не только это — поисковик также упорядочивает результаты, показывая пользователю самые релевантные в первую очередь.
По запросу «пляжы Анапы» поисковая система, скорее всего, покажет нужную статью первой в списке. Как она понимает, что именно эта статья должна быть на первом месте? Потому что статья действительно посвящена пляжам Анапы: заголовок, скорее всего, содержит фразу «Пляжи Анапы», а слова «Анапа» и «пляж», вероятно, часто встречаются в тексте. Поисковик учитывает эти признаки и выдает нужную статью выше остальных — менее релевантных, но все же связанных с запросом. Возможно, другие статьи рассказывают либо о пляжах вообще, либо об Анапе, но не о пляжах Анапы конкретно, и упоминают ключевые слова лишь вскользь.
Релевантность — это мера того, насколько контент удовлетворяет информационные потребности как пользователя, так и бизнеса. В e-commerce поиске релевантность — это не только правильный набор результатов, но и правильная их сортировка: так, чтобы позиции, участвующие в промо (которые желает продавать бизнес), отображались ближе к началу списка.
Поисковые системы делают гораздо больше, чем просто возвращают документы на основе релевантности. Поиск был бы мало полезен, если бы он не представлял релевантные документы пользователю так, чтобы это побуждало его к дальнейшему изучению. Интерфейсы поисковых систем направляют пользователей к нужному контенту с помощью множества знакомых вам функций.
В центре внимания, поисковик предоставляет пользователю список совпадающих документов. Обычно пользователь не видит весь документ, а лишь подмножество полей, которые считаются важными для понимания того, почему документ оказался в результатах. В примере с пляжами Анапы такими полями, скорее всего, будут заголовок статьи, автор, рубрика газеты (в данном случае «Путешествия»), дата и отрывок из текста статьи.
Вместо самих значений полей поисковики часто возвращают краткие фрагменты, подчеркивающие совпадения. Эти фрагменты, или хайлайты, показывают, почему именно документ соответствует запросу пользователя. Часто при чтении таких фрагментов пользователь понимает, как можно улучшить исходный запрос. Например, если «Анапский Пляж» оказалось названием местного бара, пользователь может решить изменить запрос, чтобы исключить рестораны.
Поиск также стимулирует дальнейшее исследование, показывая, как распределяются совпадающие документы по всему корпусу. Изначально Юля ограничила свой поиск статьями только из рубрики «Путешествия». Но хорошо реализованный поиск укажет, сколько статей с запросом «пляжи Анапы» найдено и в других рубриках газеты. Такая агрегированная информация часто отображается в боковой панели в виде набора фильтров, также известных как фасеты. Возможно, та статья, которую Юля вспомнила, была о туристическом буме на пляжах Анапы и находилась в рубрике «Экономика». Увидев это в фасетах, она может выбрать соответствующую категорию, чтобы отфильтровать результаты и оставить только статьи из нужной рубрики.
Как именно поисковой системе предоставляется контент для поиска?
Сначала данные извлекаются из источника, в котором хранится информация. Это может быть база данных, текстовые файлы, веб-страницы или любой другой источник. Эти необработанные данные преобразуются в документы, описанные ранее. Документы могут быть дополнительно обогащены — в них добавляются новые поля с внешней информацией, которая помогает при сопоставлении или ранжировании.
Анализ преобразует значения полей (обычно текст) в элементы, называемые токенами. В случае текста токены, как правило, соответствуют словам, например: «лучший», «анапа», «пляж». Вы можете заметить, что эти токены могут немного отличаться от оригинальных слов. Слово «и» может быть отброшено, токены приведены к нижнему регистру, а окончание множественного числа в слове «пляжи» может быть удалено. Почему так?
Токен, извлечённый из статьи, и токен из будущего поискового запроса должны точно совпадать, чтобы считаться совпадением. Поиск часто использует языковые эвристики, чтобы упростить слова до базовой формы. Например, анализ текста удаляет заглавные буквы (Анапа → анапа), суффиксы (кусочек → кусок), формы множественного числа (пляжи → пляж) и другие шаблоны.
Ранее упоминалось понятие признаков (features). В машинном обучении признаки — это описательные характеристики классифицируемых объектов. Например, при классификации фруктов это могут быть цвет, вкус и форма. В полнотекстовом поиске токены, полученные в результате анализа, становятся основными признаками, которые используются для сопоставления запроса пользователя с документами в индексе.
После завершения анализа документы индексируются: токены, полученные на этапе анализа, сохраняются в структурах данных поисковой системы для последующего поиска. Кроме того, сохраняются исходные, неразбитыe на токены текстовые поля, чтобы их можно было отображать пользователю в результатах поиска. Числовые поля также сохраняются — они могут использоваться при вычислении релевантности и ранжировании.
Структуры данных
В основе любой поисковой системы лежит небольшой набор высоко оптимизированных структур данных, которые позволяют находить документы и рассчитывать их релевантность. Понимание этих структур и того, как они используются — обязательный шаг к пониманию внутренних механизмов работы поискового движка.
Осознав механику этих процессов, вы сможете использовать поисковую систему для построения интеллектуальных и релевантных поисковых решений, которые на первый взгляд могут казаться «умными» или даже «волшебными».
Инвертированный индекс
Самый яркий пример инвертированного индекса можно обнаружить во многих печатных изданиях в конце книги — это называется Книжный указатель

Инвертированный индекс состоит из двух основных компонентов:
-
Словарь терминов — отсортированный список всех терминов (слов), встречающихся в определённом поле в наборе документов.
-
Список вхождений (postings list) — для каждого термина из словаря хранится список документов, в которых этот термин содержится.
Чтобы понять это более наглядно, давайте рассмотрим пример. Представим набор документов, как указано в следующем фрагменте.
0: Один ботинок, два ботинка, красный ботинок, синий ботинок.
1: Синие туфли — лучшие туфли.
2: Лучшее платье — это то самое красное платье.Словарь терминов и список вхождений (postings list) для этого простого набора документов представлены в следующих двух списках соответственно.
Словарь терминов:
ботинок → 0
два → 1
лучший → 2
один → 3
платье → 4
самый → 5
синий → 6
туфли → 7
красный → 8 Список вхождений (postings list):
0 (ботинок) → [0]
1 (два) → [0]
2 (лучший) → [1,2]
3 (один) → [0]
4 (платье) → [2]
5 (самый) → [2]
6 (синий) → [0,1]
7 (туфли) → [1]
8 (красный) → [0,2]
И словарь терминов, и список вхождений — это маппинги.
Терминологический словарь сопоставляет термины с порядковыми номерами, которые однозначно идентифицируют каждый термин. Как и в алфавитном указателе книги, этот словарь упорядочен лексикографически, чтобы упростить поиск терминов. Получив порядковый номер термина, вы используете соответствующий список вхождений, чтобы определить, в каких документах встречается этот термин — аналогично номерам страниц в алфавитном указателе книги.
Давайте разберем пример, чтобы сделать это более наглядным.
Допустим, вы ищете все документы, содержащие термин «красный».
Сначала вы находите «красный» в терминологическом словаре и видите, что у него идентификатор 8.
Затем вы переходите к списку вхождений и находите записи, связанные с термином 8 — в этом случае список указывает на документы 0 и 2.
Обратившись к исходным документам, вы видите, что документы 0 и 2 действительно содержат слово «красный», а документ 1 — нет.
В этом примере стоит отметить, что мы немного упростили ситуацию.
Эти документы содержат только одно поле с предложениями.
Но на практике документы обычно содержат несколько полей: заголовок, описание, адрес, цена и так далее.
В таком случае принцип не меняется: по-прежнему существует один инвертированный индекс, но термины в нем сначала сортируются по полям, а затем — лексикографически внутри каждого поля.
Терминологический словарь и список вхождений — это ключевые элементы структуры данных инвертированного индекса, поскольку именно они позволяют быстро сопоставлять документы с терминами запроса.
Однако для того, чтобы поисковая система могла выдавать релевантные результаты и обеспечивать возможность исследования, Lucene добавляет к индексу дополнительные структуры данных и метаданные.
Многие из этих компонентов являются необязательными. В некоторых случаях их отключение может служить оптимизацией. В других — наоборот, включение таких структур данных позволяет реализовать более богатую релевантность или дополнительные функции поиска.
В таблице перечислены одни из наиболее важных типов информации, которые часто ассоциируются с инвертированным индексом.
| Название | Описание |
|---|---|
| Частота документов (Doc frequency) | Количество документов, содержащих определённый термин, или длина списка вхождений (postings) для данного термина. В примере выше частота документа для термина «ботинок» равна 1, так как он встречается в документе 0. Частота документов полезна при оценке релевантности, так как показывает значимость термина. Например, слово «потому» имеет высокую частоту, что указывает на его низкую дискриминирующую ценность для оценки релевантности документа. |
| Частота термина (Term frequency) | Количество раз, которое термин встречается в конкретном документе. В примере выше термин «ботинок» встречается 4 раза в документе 0. Частота термина помогает определить важность документа для данного запроса: чем выше частота, тем более релевантен документ. |
| Позиции термина (Term positions) | Позиция слова в тексте часто важна для поиска. Запрос: «новостройки в Москве» Теперь рассмотрим два текста: 1. Документ A: «Компания занимается продажей новостроек в Москве и Подмосковье.» 2. Документ B: «В Москве открылась новая выставка, посвящённая архитектуре. Среди экспонатов — макеты новостроек со всей страны.» Почему позиция важна? - В документе A слова «новостройки» и «в Москве» находятся рядом и образуют логическое словосочетание, точно отражающее поисковый запрос. - В документе B оба слова тоже есть, но находятся далеко друг от друга и не составляют связную идею — документ менее релевантен. Позиции термина — это список номеров, указывающих, где в документе встречается термин. Например, позиции слова «ботинок» в документе 0 — это 1, 3, 5, 7. Эта информация позволяет находить документы с точным совпадением фраз. |
| Смещения термина (Term offsets) | Один из лучших способов показать пользователю, почему документ соответствует запросу — это выделить в тексте совпадающие фрагменты. Повторный анализ текста для подсветки может быть медленным, поэтому при индексации сохраняются начальные и конечные смещения символов для терминов. Тогда во время поиска достаточно вставить теги подсветки в нужные места. |
| Дополнительные данные (Payloads) | Каждому термину в индексе можно присвоить произвольные данные. Примеры: тег с частью речи для улучшения ранжирования или оценка термина (например, «Анапа» в одном контексте может иметь вес 100, а в другом — 59). |
| Сохраняемые поля (Stored fields) | Данные, хранящиеся в инвертированном индексе, полезны для поиска, но это переработанная версия исходного документа. Поля, которые нужно отображать пользователю, сохраняются отдельно как сохраняемые поля. Такие поля занимают много места, поэтому часто разработчики предпочитают не хранить их в поисковом движке, а извлекать при необходимости из исходной системы. |
| Значения (Doc values) | Часто в расчёты релевантности включают вспомогательные значения. Например, в e-commerce-поиске может быть повышен рейтинг товаров, находящихся на распродаже или имеющих высокую маржинальность. Также пользователям нередко предоставляется возможность сортировать результаты поиска по таким метрикам, как цена или популярность. Структура данных doc values обеспечивает быстрый доступ к таким вспомогательным значениям и используется при сортировке, оценке релевантности (scoring) и группировке документов. |
| При перемещении данных в хранилище часто говорят о процессе извлечения, преобразования и загрузки информации, известном как ETL (Extract, Transform, Load). Данные извлекаются из места хранения, преобразуются в формат, подходящий для целевого хранилища, а затем загружаются в него. В следующем разделе мы будем использовать терминологию ETL, чтобы описать, как данные попадают в поисковую систему. |
ETL
Поскольку мы говорим именно о поисковом движке, можно быть более конкретными в описании шагов ETL-процесса, специфичных для поиска. Как показано на рисунке, эти шаги включают: извлечение (extraction), обогащение (enrichment), анализ (analysis) и индексацию (indexing).
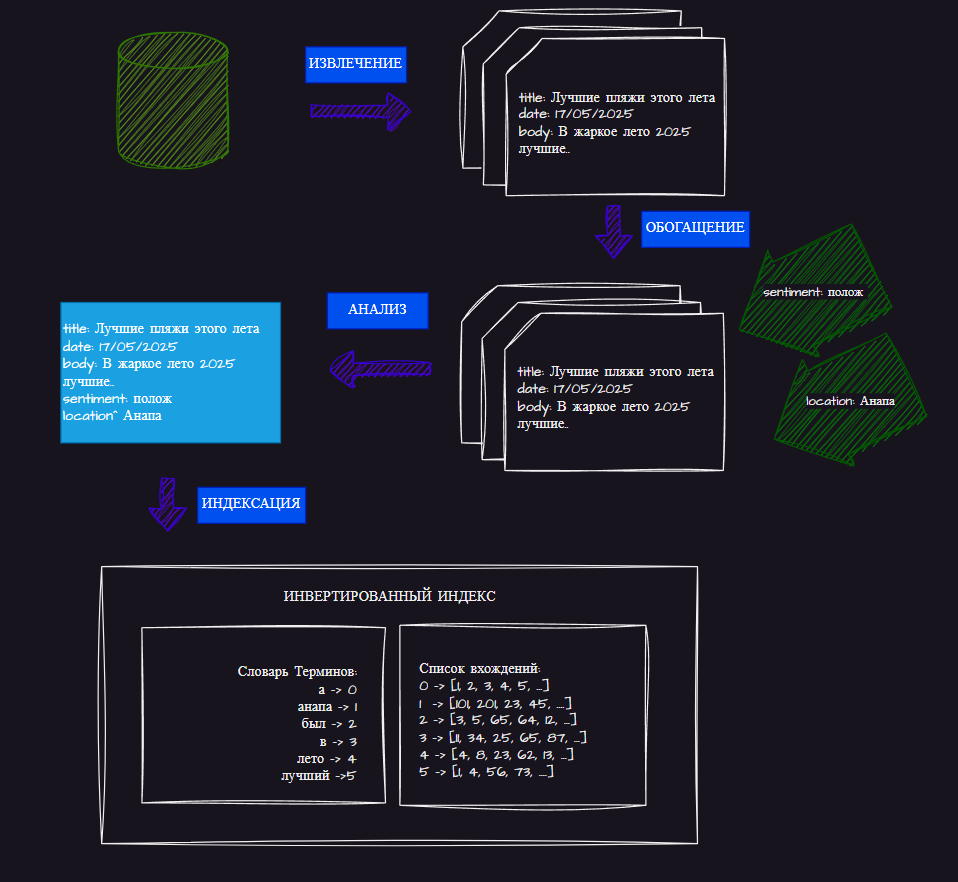
-
Извлечение — это процесс получения документов из их источников.
-
Обогащение — необязательный шаг, добавляющий к документам информацию, полезную для оценки релевантности.
-
Анализ — как вы уже видели ранее, процесс анализа преобразует текст или данные документа в токены, позволяющие осуществлять сопоставление.
-
Индексация — процесс помещения данных в соответствующие структуры данных.
Извлечение
Создание документов, которые легко извлекаются поисковой системой, может быть столь же важным для релевантности, как и работа с внутренними механизмами самой системы поиска.Курация контента и внимательное проектирование полей документа часто определяют, будет ли решение задачи релевантности простым или сложным.
Основа этой работы заключается в управлении процессами извлечения и обогащения данных.
У данных может быть множество источников. Если вам повезло, документы можно легко получить из базы данных или внешнего хранилища данных. В таком случае извлечение может сводиться к выполнению простого запроса, чтобы выгрузить необходимые данные.
Если повезло меньше — возможно, придётся искать документы вручную — например, сканировать веб-страницы или файловые системы.
А если совсем не повезло…
Возможно, вы обнаружите, что ваши данные заперты внутри файлов, которые требуют сложной дополнительной обработки (например, документы MS Word, PDF-файлы или, что хуже всего, изображения отсканированного текста). Но вне зависимости от ситуации, конечным результатом извлечения является набор документов, который отправляется в поисковую систему.
Главная мысль здесь — контролируйте процесс извлечения данных. Существует множество стратегий, проектов, плагинов и готовых решений для преобразования данных из исходных источников в формат, пригодный для поиска. Возможных комбинаций так много, что для их описания понадобилось бы не один десяток книг.
Но вам важно понимать, как именно устроен ваш процесс извлечения, чтобы вы могли управлять структурой создаваемых документов. Если просто бездумно загружать данные в поисковую систему в их исходном виде, это может серьёзно ограничить ваши возможности.
Обогащение
Во время этапа обогащения документы, полученные на этапе извлечения, дополняются дополнительной информацией. Это может быть важным шагом при построении релевантного поиска, поскольку часто сырые, извлечённые документы не содержат достаточно насыщенных признаков, чтобы их можно было эффективно сопоставить с пользовательскими запросами.
Обогащение документа можно условно разделить на три основные категории:
1. Очистка данных
Если вы хотите обеспечить высококачественный пользовательский опыт, обычно стоит потратить время на анализ документов, поиск ошибок (например, опечаток или дубликатов), и их исправление.
Иначе пользователи могут не найти документ, если в нём есть опечатка в слове из поискового запроса. Или, напротив, они могут найти 20 дубликатов одного и того же документа, из-за чего другие, более релевантные материалы будут вытеснены с первой страницы выдачи.
2. Обогащение существующих данных
Часто имеющиеся данные можно дополнительно обработать, чтобы расширить уже имеющиеся признаки.
Например:
-
Использовать машинное обучение для классификации или кластеризации документов.
-
Применить анализ тональности, чтобы определить, насколько текст документа позитивный или негативный по тону.
Возможности здесь по-настоящему безграничны. После добавления новых метаданных, они могут служить ценными признаками для улучшения поиска и фильтрации.
3. Объединение с внешними источниками
Иногда нужно влить новые данные из внешних источников.
Например, в e-commerce товары, представленные в магазине, часто поступают от внешних поставщиков. Их данные могут быть неполными.
В этом случае:
-
Используя идентификаторы продуктов, можно подтянуть недостающие данные, такие как названия, описания и характеристики.
-
В ряде случаев недостающие описания можно заполнить вручную.
Цель обогащения — дать пользователю максимум возможностей для того, чтобы он нашёл нужный документ. А это означает: больше признаков для поиска и богаче функциональность самой поисковой системы.
Анализ
То, каким образом текст (и другие типы данных) трансформируется в токены, определяет, как будет происходить сопоставление в поисковой системе.
Как инженер по релевантности, вы будете тратить много времени на тонкую настройку анализа, чтобы контролировать, в каких случаях происходят совпадения. Давайте углубимся в этот процесс.
После того как документы были извлечены из хранилища и (возможно) обогащены, они, наконец, отправляются в поисковую систему, где проходит этап анализа.
Во время анализа поисковая система обрабатывает данные в документах и преобразует их в токены, которые затем сохраняются во внутренних структурах данных поискового движка.
Как упоминалось ранее, токены — это символы (единицы), представляющие содержимое поля документа. Часто токены совпадают со словами в текстовом поле.
Не думайте, что токены обязательно должны соответствовать словам — практически любой тип данных может быть преобразован в токены.
Одна из основных функций поискового движка — сопоставление токенов. Именно через сопоставление токенов поисковик находит документы, соответствующие запросу пользователя. С одной стороны, текст и другие данные из документов проходят анализ — то есть преобразуются в токены — и сохраняются в инвертированный индекс. С другой стороны, запросы также анализируются и преобразуются в токены. Документы, в которых есть токены, совпадающие с токенами запроса, считаются совпадениями для поиска.
Главный момент, который стоит подчеркнуть: вы, как инженер по релевантности, контролируете процесс анализа. Изменения в способе преобразования данных в токены радикально влияют на релевантность поиска. Например если фраза будет разбита на токены, но токены не будут приведены к нижнему регистру, то запрос от пользователя, который не содержит заглавные буквы, приведет к пустой выдаче поскольку токены документа и запроса не совпадают.
Поисковые системы «тупы»: если токены из запроса и документа не совпадают в точности — побайтово — документ не будет считаться совпадением!
Именно поэтому анализ настолько важен. Именно поэтому вы тратите столько времени на нормализацию текста — чтобы токены из запроса совпадали с токенами документа, даже если исходный текст документа немного отличается от текста запроса.
ТОКЕНЫ КАК ФИЧИ
Всё это тесно связано с нашей основной темой — поисковыми признаками. Точно так же, как красный цвет и круглая форма могут описывать яблоко, токены, полученные в результате анализа, служат признаками, описывающими документ. Продолжая эту аналогию, если вы хотите найти яблоко в магазине, вы ищете фрукт, который одновременно красный и круглый. В мире поиска всё то же самое: пользователь, который ищет документ об установке сплит-системы в загородном доме, вводит соответствующий запрос в поисковую систему, и та анализирует запрос, извлекает признаки (токены), а затем пытается найти документы с совпадающими признаками.
Таким образом, в ходе обсуждения поисковых признаков имейте в виду, что на практике чаще всего речь идёт именно о токенах. Мы используем слово «признак», чтобы подчеркнуть, что токен выступает в роли описательного элемента как для документа, так и для запроса.
Как вы можете себе представить, процесс анализа даёт инженеру по релевантности огромную выразительную силу в определении того, как текст и другие значения преобразуются в токены. Но, как говорится, с большой силой приходит большая ответственность. Хорошие, описательные признаки могут помочь эффективно сопоставлять запросы и документы, но неуместные или ошибочные признаки могут сделать документ совершенно недоступным для поиска!
Единственный способ убедиться, что ваш анализ создаёт качественные признаки — это досконально изучить процесс анализа. Что ж, давайте разберёмся в деталях.
КОМПОНЕНТЫ АНАЛИЗА
Анализ состоит из трёх этапов: фильтрация символов, токенизация и фильтрация токенов.
На первом этапе — фильтрации символов — символы текстовых полей могут быть изменены или отфильтрованы различными способами. Хороший пример — HTMLStripCharFilter, который принимает HTML на вход и возвращает только текст, содержащийся в HTML, игнорируя сами теги. В принципе, с помощью фильтра символов можно делать практически всё, что угодно, включая использование регулярных выражений или создание собственного фильтра.
Во время анализа можно указать любое количество фильтров символов — они будут выполняться по очереди в том порядке, в котором заданы.
Следующим этапом является токенизация. Как следует из названия, на этом этапе исходный текст преобразуется в поток токенов. Самый простой способ токенизировать текст — это разделить его по пробелам, но этого в большинстве случаев недостаточно. Почему?
Потому что в результате получаются токены, содержащие знаки препинания. Вместо этого для английского и большинства европейских языков используется стандартный токенизатор, который разделяет текст по пробелам и знакам препинания. В отличие от фильтров символов, в одной цепочке анализа может быть только один токенизатор.
Заключительный этап — это фильтрация токенов. Здесь поток токенов может быть скорректирован: токены можно изменить, добавить или удалить.
Для того чтобы правильно нормализовать токены из нашего примера, типичным выбором будет:
-
приведение всех токенов к нижнему регистру;
-
удаление часто встречающихся слов, таких как и и в (эти слова называются стоп-словами);
И, как в случае с фильтрами символов, несколько фильтров токенов могут применяться последовательно в том порядке, который задаёт инженер по релевантности.
Прежде чем мы перейдём к индексации, ещё одно замечание. Во время анализа часто сохраняется дополнительная метаинформация для каждого токена, которую генерирует процесс анализа. Наиболее распространённые метаданные — это позиции токенов (term positions) и смещения токенов (term offsets), которые полезны соответственно для поиска по фразам и подсветки текста в результатах поиска.
Также можно создавать пользовательские фильтры токенов, которые добавляют произвольную метаинформацию к токенам в виде значений, называемых payloads. Но будьте осторожны: все эти данные могут значительно увеличить объём хранения. Если вы решите поэкспериментировать с payloads, лучше делать это умеренно.
Индексация
Это процесс сохранения данных во внутренние структуры инвертированного индекса. Хотя техническая реализация индексации сама по себе является инженерным шедевром, основной фокус при индексации делается на производительности вычислений и управлении ресурсами, а не на вопросах релевантности. Однако некоторые решения, принимаемые во время индексации, всё же могут повлиять на релевантность — в частности:
-
какие части данных необходимо индексировать;
-
какие структуры данных использовать.
Самое важное — это решить, какие поля нужно индексировать, какие — хранить, а какие — и индексировать, и хранить. В общем смысле, термин “индексация” относится к процессу сохранения данных в поисковой системе. Но в контексте структуры данных есть более точные значения:
-
Индексация — это процесс обновления инвертированного индекса извлечёнными токенами, чтобы по этим полям можно было выполнять поиск. Поле становится доступным для поиска, только если оно индексируется.
-
Хранение — это сохранение исходного, неизменённого содержимого поля в структуре данных stored fields, чтобы можно было отобразить эти данные пользователю в результатах поиска.
Поисковая система может отображать данные пользователю только в том случае, если они сохранены. В целях оптимизации некоторые инженеры хранят как можно меньше данных, ограничиваясь, например, только уникальным идентификатором. Для отображения содержимого полного документа такие решения предполагают получение данных из внешнего источника. Другие, напротив, предпочитают хранить данные в поисковой системе из соображений удобства или чтобы избавиться от зависимости от внешних систем.
Хранение данных также позволяет системе подсвечивать совпадения в результатах поиска. Как мы уже обсуждали, это может помочь пользователю понять, почему найден именно этот документ, и скорректировать запрос для дальнейшего уточнения.
Кроме индексации и хранения данных, вы можете включить или отключить использование множества дополнительных структур данных, приведённых в таблице ранее. Их использование зависит от ваших поисковых требований.
Последний момент, связанный с релевантностью и касающийся индексации: документы индексируются пакетами. После обработки определённого количества документов или по истечении заданного времени они фиксируются (commit) в индексе. Только после commit’а документы становятся доступными для поиска. Поэтому между отправкой документа в систему и его появлением в результатах поиска может быть небольшая задержка. Это важно учитывать при работе над релевантностью.
Поиск и извлечение документов
Ранее мы рассмотрели, как получить набор документов, содержащих один термин: вы находите термин в словаре терминов, берёте соответствующий список вхождений (postings) — и готово. Этот список содержит документы, где встречается данный термин.
Но что делать, если вы хотите найти документы, содержащие сразу несколько терминов? Именно для этого существует булев поиск. Булев поиск объединяет результаты нескольких запросов, чтобы точнее управлять тем, какие документы будут возвращены. Например: ("ботинок" И "синий").
Давайте посмотрим, как можно реализовать типичные булевы операторы (AND, OR, NOT) с помощью содержимого инвертированного индекса.
Сначала оператор AND. Обратимся к примеру и подумаем, как найти документы, содержащие оба термина — “ботинок” и “синий”. Сначала нужно получить списки вхождений (postings) для обоих терминов, а затем найти те документы, которые есть в обоих списках.
Поскольку списки вхождений — это отсортированные списки номеров документов, алгоритм нахождения их пересечения достаточно простой и может быть реализован, например, на Python.
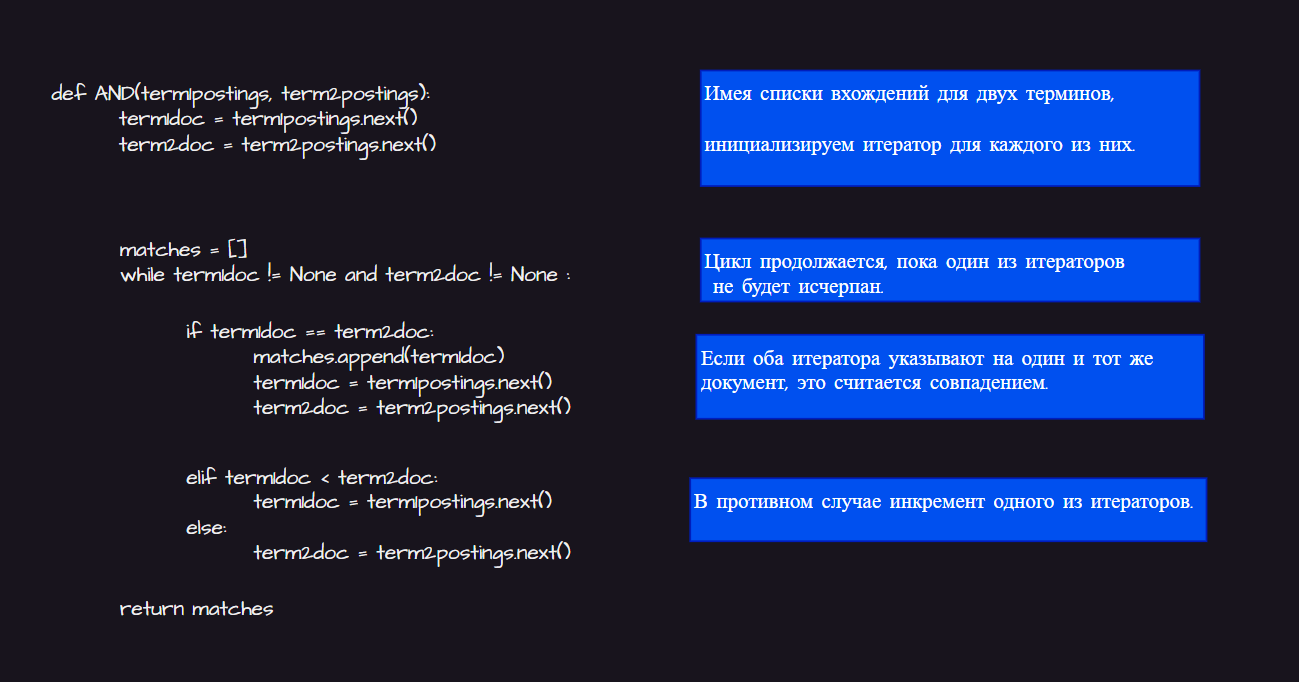
Всё, что вы здесь делаете — это итерация по двум спискам вхождений одновременно: начиная с первого документа в обоих списках, вы последовательно увеличиваете тот список, в котором указатель стоит на меньшем значении ID документа. Каждый раз, когда ID документов в обоих списках совпадают, этот ID добавляется в рабочий список совпадений. Алгоритм останавливается и возвращает найденные совпадения, когда один из списков заканчивается.
Переход от оператора AND к другим булевым операциям довольно прямолинеен. Для поиска по OR вместо нахождения пересечения списков вхождений вы возвращаете объединение всех документов из обоих списков. Для оператора NOT вы берёте список совпадений и вычисляете все ID документов, которые не входят в этот список (так как списки вхождений удобно отсортированы, эта операция оказывается довольно простой).
Булевый поиск легко расширяется для выполнения сложных составных булевых запросов и запросов по нескольким полям. Вам не нужно ничего особенного для реализации этой функциональности. В случае составных запросов стоит заметить, что входные аргументы и выходные значения функции AND из листинга — это списки ID документов. То же самое относится и к операторам OR и NOT. Благодаря этому булевы функции можно комбинировать между собой для построения произвольно сложных запросов. Расширение на многопольные запросы также просто, потому что независимо от того, в каком поле находится термин, списки вхождений всё равно ссылаются на те же документы с использованием одинаковых ID, так что списки из любых полей и любых терминов можно использовать вместе в описанном выше алгоритме.
Булевы запросы в Lucene-поиске (MUST / MUST_NOT / SHOULD)
В Lucene есть тип запроса под названием BooleanQuery, который используется для реализации поведения, описанного ранее. Однако его название может ввести в заблуждение, и поведение не совсем такое, какое можно было бы ожидать. Вы могли бы подумать, что BooleanQuery использует логические операторы AND, OR и NOT — но это не так! Вместо этого он использует три типа условий, которые обеспечивают схожую функциональность, но с немного отличающейся семантикой: SHOULD, MUST и MUST_NOT.
-
Условие типа MUST должно обязательно совпасть в документе — в противном случае документ не будет считаться подходящим.
-
Условие типа SHOULD может как совпасть, так и не совпасть в документе, но документы, в которых оно совпало, будут оценены выше, чем те, в которых совпадения нет.
-
Если документ содержит совпадение по условию MUST_NOT, он не будет считаться подходящим, даже если совпадают условия
MUSTилиSHOULD.
BooleanQuery может содержать любое количество условий SHOULD, MUST и MUST_NOT. Но если запрос не содержит условий MUST, то документ будет считаться подходящим только если выполнено хотя бы одно условие SHOULD.
Прежде чем перейти к примеру, поговорим о синтаксисе запросов в Lucene и о том, как представляется BooleanQuery. Elasticsearch и Solr используют этот синтаксис при отображении отладочной информации о запросах. В синтаксисе Lucene запросы MUST и MUST_NOT обозначаются префиксами:
-
Условия
MUSTобозначаются символом+перед термином. -
Условия
MUST_NOT— символом-. -
Условия
SHOULDне имеют префикса.
Рассмотрим простой пример запроса и набор документов…
Запрос:
черный +кошка -собака
Документы:
-
моя кошка убежала под диван
-
чёрные кошки загадочны
-
собака испугала чёрную кошку
Этот запрос ищет документы, которые обязательно должны содержать слово кошка, желательно чтобы содержали слово чёрный и не должны содержать слово собака.
Таким образом, документы (1) и (2) являются подходящими, потому что оба содержат обязательное слово кошка. Из них документ (2) получит более высокий рейтинг, так как содержит также черный, пусть и не обязательное, но желательное слово.
Хотя документ (3) тоже содержит черный и кошка, он не считается подходящим, потому что содержит запрещённое слово собака.
Также в Lucene можно группировать условия с помощью скобок. Вот пример составного запроса:
+(кошка собака) черный
Этот запрос означает: документ должен содержать либо кошка, либо собака (или оба) (это обязательное условие за счёт +), и желательно — слово черный.
Возможно, вы всё ещё задаётесь вопросом — почему Lucene использует такие странные обозначения, а не стандартные логические операторы AND, OR и NOT? Дело в том, что операторы Lucene обладают более “размытыми” семантиками, что делает их более подходящими для поиска, в отличие от строгих логических операторов, применяемых для точного включения или исключения множеств.
Вернёмся к нашему первому примеру:
черный +кошка -собака
Как бы вы выразили этот запрос с помощью AND, OR и NOT?
Ответ будет выглядеть так:
(кошка OR (черный AND кошка)) AND NOT собака
Как видно, синтаксис Lucene оказывается более простым и лаконичным. Он помогает пользователям выражать сложные запросы короче и понятнее.
Позиционное и фразовое совпадение
Относительное положение слов в тексте часто несёт важную семантическую нагрузку.
Именно поэтому в Lucene существует фразовый запрос, который учитывает позицию терминов. В синтаксисе запросов Lucene фразы заключаются в кавычки, например:
“туфли для костюма”
Поисковая система обрабатывает такие запросы в два этапа:
-
Находит все документы, содержащие все термины фразы (в примере:
костюмитуфли). -
Фильтрует документы, в которых слова не идут подряд, например, удалит «этот костюм хорошо сочетается с твоими туфлями», но сохранит «купите эти элегантные туфли для костюма».
Результатом фразового запроса является список ID документов, поэтому такие запросы можно использовать в составе булевых запросов Lucene.
Фразовые запросы зависят от позиции терминов.
По умолчанию поддержка позиций включена как в Elasticsearch, так и в Solr.
Дополнительно можно использовать параметр phrase slop — он позволяет ослабить требование строгого следования слов в фразе.
Кроме того, в Lucene есть специальная библиотека span-запросов, которая позволяет ещё тоньше управлять порядком и положением терминов.
Исследование данных: фильтры, фасеты и агрегации
При поиске по большому количеству документов часто бывает полезно отфильтровать коллекцию, чтобы получить более управляемый рабочий набор результатов.
Например, если вы ищете цифровую камеру Nikon на Ozon, вам не нужно видеть товары из других категорий, не относящихся к электронике. Кроме того, вы, скорее всего, имеете ценовой диапазон — скажем, если вы любитель, то вряд ли вам интересна модель Nikon D4S за 600 000.
Такое фильтрование возможно благодаря способности поисковой системы быстро находить документы.
Но здесь есть важное различие: такая фильтрация чаще всего выполняется по полям с низкой кардинальностью (например, поле категория) или по диапазонам числовых или датированных полей (например, поле цена).
фасеты (facets) дают пользователю аналитический взгляд на результаты поиска. Фасеты, обычно представляют собой список атрибутов, по которым можно отфильтровать результаты, с указанием количества документов для каждого значения.
Такой интерфейс помогает пользователю лучше ориентироваться в коллекции и быстро находить наиболее релевантные элементы. Таким образом, фасеты выступают как механизм обратной связи по релевантности для пользователей.
Структуры данных Lucene поддерживают сложную многоуровневую фильтрацию, группировку и агрегацию, но фасеты показывают лишь малую часть этой мощности.
К счастью, в Elasticsearch есть агрегации (aggregations), которые позволяют выполнять мощную аналитическую обработку данных в реальном времени (OLAP):
-
фильтрация по значениям определённых полей,
-
группировка по другим полям,
-
агрегации (сумма, среднее, количество, минимум, максимум и т. д.) по значениям других полей.
Хотя агрегации чаще всего используют продвинутые пользователи, они дают поиску беспрецедентную гибкость для анализа, срезов и сводки набора документов.
Сортировка, ранжирование результатов и релевантность
Как и многие другие хранилища данных, поисковые системы позволяют извлекать документы с заданной сортировкой.
Порядок может определяться:
-
числовым значением поля типа
floatилиinteger, -
или лексикографическим порядком строкового поля.
Кроме того, порядок сортировки может задаваться функцией, в которой одно или несколько значений полей используются для вычисления числового показателя, по которому и осуществляется сортировка.
Но в типичном сценарии использования поиска сортировка явно не задаётся. Вместо этого документы, соответствующие запросу, возвращаются в порядке убывания релевантности.
Напомним, что в информационном поиске релевантность — это мера того, насколько хорошо результаты удовлетворяют информационную потребность пользователя.
мы рассматриваем более широкое определение: релевантные результаты должны удовлетворять и потребности пользователя, и цели бизнеса (например, продвигать продукты с высокой маржинальностью).
Иногда интересы пользователя и бизнеса противоречат друг другу, и найти баланс между ними бывает непросто.
Давайте сделаем это абстрактное понятие более конкретным:
Релевантность определяется функцией ранжирования (ranking function).
Эта функция:
-
получает данные из запроса и из каждого подходящего документа,
-
и для каждого документа вычисляет оценку (score) — насколько хорошо он соответствует запросу.
Функция ранжирования может быть довольно сложной. Рассмотрим пример: поиск фильмов.
Допустим, каждый документ о фильме содержит три поля:
-
title(название), -
description(описание) — оба являются текстовыми полями, -
и
popularity— числовое поле.
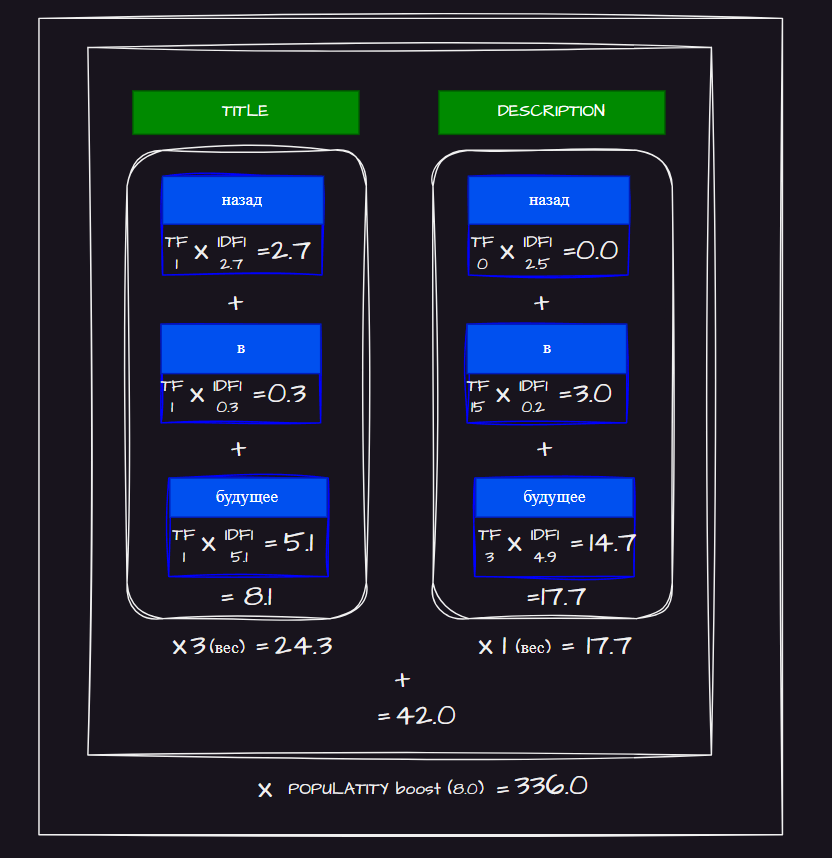
Пусть наш запрос: “назад в будущее” (back to the future).
Прежде чем ранжировать документы, нужно найти те, которые соответствуют запросу.
Это делается путём анализа запроса (так же, как анализируются документы — извлекаются токены и находятся соответстви).
Также документы могут быть отфильтрованы по дополнительным пользовательским критериям.
Имея список совпадающих документов, мы начинаем их оценивать с помощью функции ранжирования.
Как показано на рисунке, структура функции ранжирования иерархическая.
На самом глубоком уровне:
-
Функция вычисляет частотную оценку — насколько часто конкретный термин запроса встречается в конкретном поле документа (term frequency).
-
Эта оценка умножается на коэффициент, зависящий от:
-
частоты этого термина в коллекции документов (document frequency),
-
и от того как много терминов содержит поле документа, в котором он встречается.
-
Этот множитель становится больше для редких слов и небольших полей.
Так, в нашем примере с запросом “назад в будущее” любой документ, в котором в поле описания часто встречается слово “будущее”, получит более высокий балл за счёт частоты употребления этого слова и относительной редкости термина “будущее” в корпусе.
Для сравнения, документы, содержащие слово “в” , получат совсем незначительное повышение оценки, так как это очень распространённый термин.
На следующем уровне функции ранжирования баллы по терминам внутри одного поля объединяются. Обычно термины входят в конструкцию SHOULD (в логическом запросе Lucene). Не обязательно, чтобы присутствовали все термины — чем больше совпавших, тем выше итоговая оценка документа. В нашем примере документ, содержащий термины “назад” и “будущее”, будет иметь больший вес, чем документ, содержащий только один из этих терминов.
Такое интуитивное поведение конструкции SHOULD — ещё одна причина, по которой Lucene использует операторы MUST, SHOULD и MUST_NOT, а не стандартные логические AND, OR, NOT.
Обычно запросы структурируются так, чтобы одновременно искать по нескольким полям. Как инженер по релевантности, вы можете задавать числовые коэффициенты для полей, чтобы указать, насколько важно то или иное поле.
Например, вы можете проиндексировать поле title дважды: один раз с обычным анализом, другой — с учётом типичных орфографических ошибок. В таком случае совпадение с полем без ошибок должно весить значительно больше, чем совпадение с полем, содержащим опечатки. Оценки по всем полям можно затем либо сложить, либо взять максимальную из них.
Наконец, инженер по релевантности может дополнительно применить мультипликативный или аддитивный буст (повышающий коэффициент), основанный на числовом значении какого-либо поля или функции, использующей одно или несколько значений.
Именно здесь часто вступает в силу «бизнес-логика» поиска. В нашем примере с поиском фильмов, вероятно, будет выгодно повышать оценку более популярных фильмов, поскольку они лучше продаются, чем старые.
Поэтому можно задать финальный балл как произведение общей оценки по всем полям и значения поля популярность. Или, если это слишком сильный буст, можно использовать функцию, которая мягко повышает оценку в зависимости от популярности (например, взять логарифм от значения поля).
Как инженер по релевантности, вы обладаете полной свободой в настройке функции ранжирования под любую цель!